Kubernetes Deployment Patterns¶
These are the deployment patterns you can use when deploying your WSO2 Micro Integrator-based integration solutions in a Kubernetes environment.
When you deploy your integrations, the main concern is to ensure high availability and scalability of your system. Therefore, you need to decide upon the number of worker nodes and the number of replicas that are required for the purposes of scaling the deployment and ensuring high availability.
Single Replica¶
The following diagram depicts a single worker node deployment, which contains a single pod (single replica).
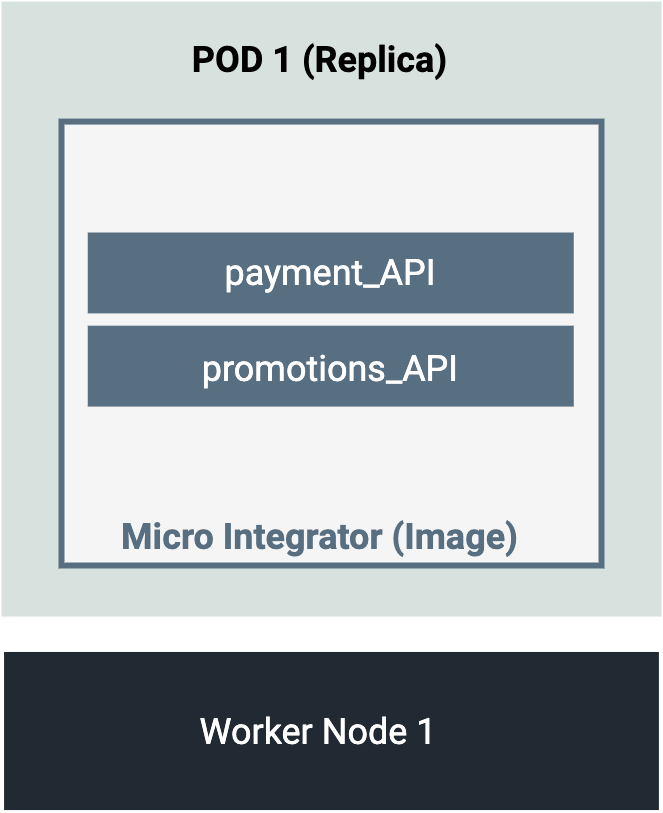
A single worker node will reduce your management overheads when you build an on-premise cluster (does not apply to cloud instances). Also, there will be lower costs and resource requirements when compared to a multiple node cluster.
Load balancing¶
The single replica deployment is not recommended if you expect a high amount of traffic to your deployment. Because there is only one replica, it is not possible to balance a high workload across multiple instances.
High availability¶
The failure of this single worker node will take down the entire Micro Integrator deployment (because we don't have an additional node to take over the workload). Also, if there is a failure in the single pod, there will be a downtime before a new pod is spawned again. This downtime can vary depending on the server_startup_time + artifact_deployment_time, which could lead to a significant downtime in your cluster. If this downtime is acceptable and does not negatively impact your requirements, this approach may be the easiest way for you to get started. Otherwise, to achieve high availability, you require more than one worker node (which avoids single point of failure) and multiple replicas of the pod (which avoids pod downtime).
Multiple Replicas¶
The following diagram depicts a kubernetes cluster with multiple replicas of an integration deployment, which is scaled across multiple worker nodes.
Note
In this example, one node only carries one replica of a pod. However, depending on the capacity of your worker node, you can maintain multiple pod replicas in a single worker node.
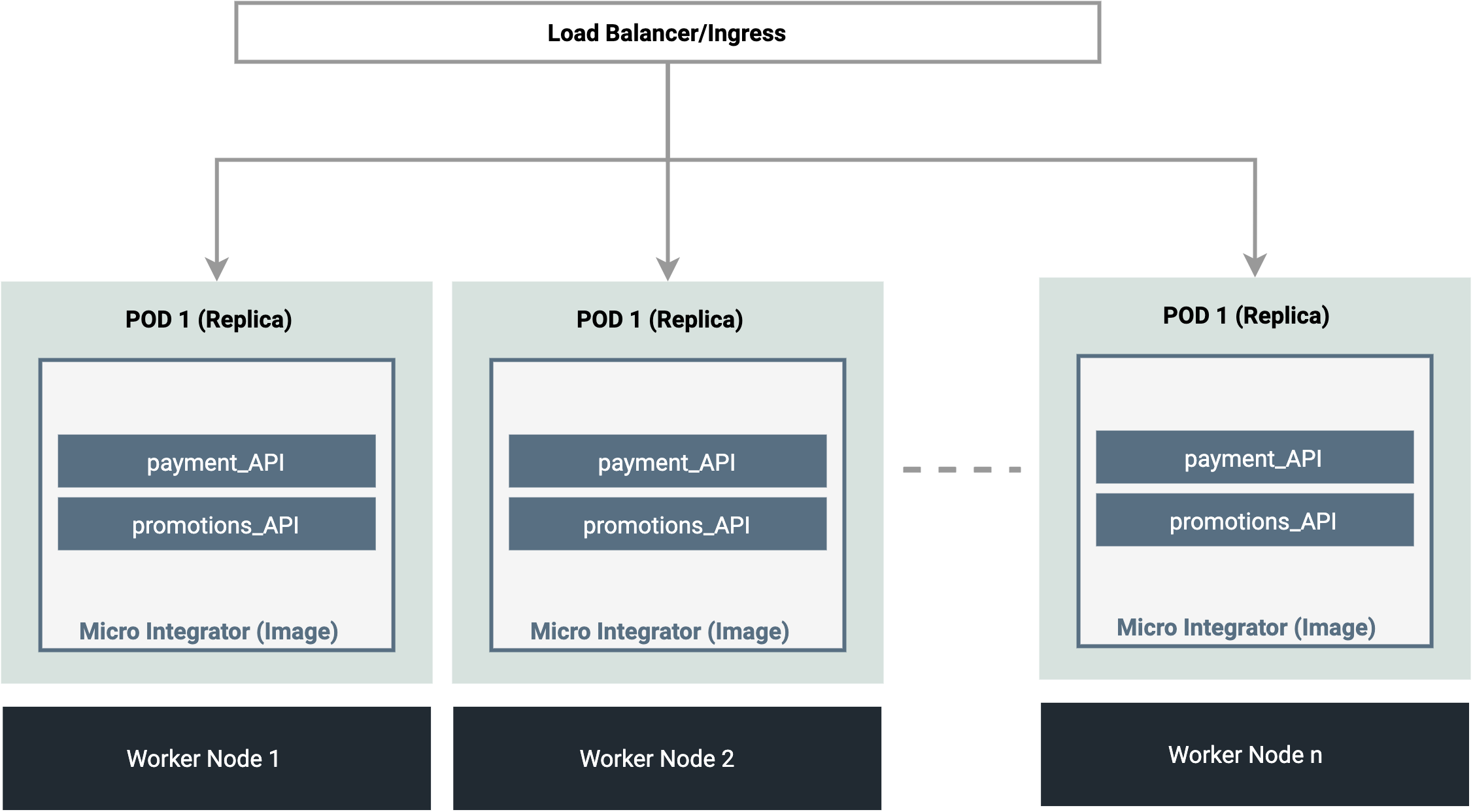
When you have multiple instances of an application, you need a way to distribute the traffic to all of them. Therefore, the cluster should be fronted by an Ingress or an external load balancer service (given that your Kubernetes environment supports external load balancers) that will distribute network traffic to all pods of the exposed deployment.
Load balancing¶
This deployment pattern is suitable for handling high incoming traffic because the workload is shared by multiple instances (replicas) of the deployment. The ingress or external load balancer that fronts the deployment distributes the workload across replicas.
High availability¶
This approach ensures high availability in your cluster. If one worker node fails, the traffic will be routed to another worker node. Similarly, if one pod replica fails, the traffic will be routed to another replica that runs concurrently at a given point of time. The pods will not experience any downtime because new pods don't need to be spawned everytime one pod fails.
Rolling updates¶
Because there are multiple replicas (i.e., multiple instances of the same deployment) running, you can apply rolling updates with zero downtime.
Multiple Replicas (with Coordination)¶
Most of the integration solutions that you develop can be deployed using a single Micro Integrator container. That is, as explained in the previous deployment pattern, you can have multiple replicas of a single pod. Because most of these integration flows are stateless (does not need to persist status) the multiple instances (replicas) are not required to coordinate with one other.
However, the following set of integration artifacts are stateful and requires coordination among themselves if they are deployed in more than a single instance.
- Scheduled Tasks
- Message Processors
- Polling Inbound Endpoints
- File Inbound Endpoint
- JMS Inbound Endpoint
- Kafka Inbound Endpoint
- Event-based Inbound Endpoints
- MQTT Inbound Endpoint
- RabbitMQ Inbound Endpoint
As long as you maintain a single artifact deployment for each of these artifacts, coordination is not required. You can arrange your cluster in the following manner to ensure that the same task is not deployed in multiple containers/pods in the cluster. As shown below, you can have multiple replicas of POD 1. However, POD 2 and POD 3 can only have one replica each because they contain stateful artifacts.
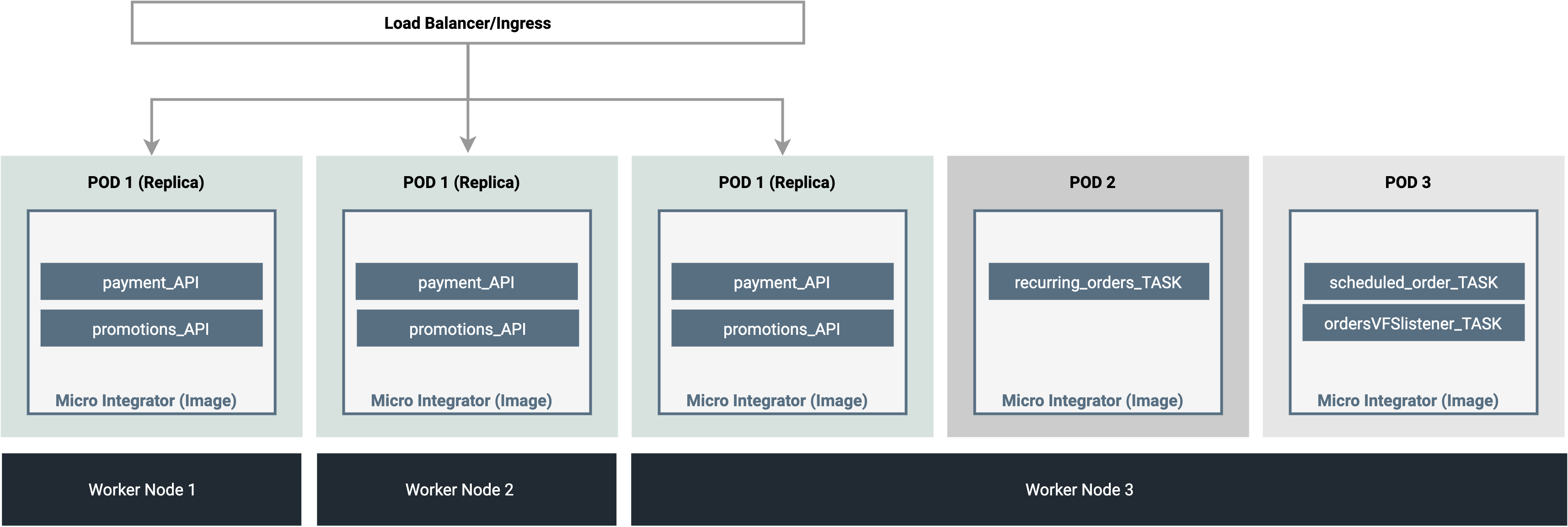
Load balancing¶
Because stateful artifacts cannot be deployed in multiple containers/pods, it is also not possible to distribute the workload for a stateful artifact when there is high traffic. However, it is possible to reduce the workload on a single worker node or pod by isolating individual stateful artifacts (or groups of selected artifacts) in individual pods.
In the example shown above, you can assume that recurringOrder_Task and schedulOrder_Task are highly-utilized scheduled tasks in your deployment. By deploying them in two separate pods (POD 2 and POD 3, you have optimized resource utilization.
High availability¶
Because stateful artifacts (that require coordination) are deployed in one container/pod in one worker node, if the node fails or if the pod fails, the pod will be spawned again in one of the running working nodes. This avoids single point of failure. However, there will be a downtime until the pod deployment becomes active again.
Top