Best Practices¶
Here are the guidelines and recommendations to design, develop, test, and deploy WSO2 integration solutions:
Design¶
Implementing enterprise integration patterns (EIPs)¶
See Enterprise Integration Patterns with WSO2 Enterprise Integrator on how to simulate the patterns in the Enterprise Integration Patterns catalog using various constructs of WSO2 Micro Integrator.
Development¶
Creating a tooling project¶
- When you start WSO2 Integration Studio, a default workspace is created to store your projects. Change the default workspace location to a preferred location that you can easily access. For information on how to change the default workspace, see Switching workspaces.
- Change the default location that your new project is created in your machine in the same way that you change the default workspace.
- Create a Maven Multi Module (MMM) project to group the projects of a specific use case.
- When you create the project structure, add it to source control such as SVN or Git.
- Use the source control command line tools to interact with files.
- When you create projects, ensure that you follow the standard Maven naming convention.
- When you define
groupid,artifactid, andversion, ensure that you follow the proper naming convention. For example, you can specify a name such asorg.acme.integration.sampleesb-demo-project1.0.0.
Creating artifacts¶
- When you create an artifact, use the proper naming convention from the start.
- If an ESB project contains many artifacts related to multiple use cases, name the artifacts by prefixing or post fixing the use case name.
- Create specific ESB projects for specific use cases. This makes it easy to manage the code/project.
- Design the ESB logic into highly cohesive and loosely coupled modules.
- Avoid creating large, complex mediation code as much as possible. Always follow the separation of concerns design principle and split lengthy logic into separate mediation components.
- When you have a common set of code, implement it in a sequence or a template that can be reused. For more information, see Sequence Template.
- Externalize endpoint and policy references using the Registry. For more information, see Managing ESB projects across environments .
- Hide sensitive information such as passwords in configuration files using Secure Vault.
Naming artifacts¶
When you create a project structure, be sure to follow the naming convention described in the table below:
Info
Therefore, give unique names for artifacts to avoid name conflicts when you have multiple projects.
| Type | Description | Format | Sample |
|---|---|---|---|
| Project name | The root directory of the project's source code. | <ProjectName> |
StudentInformationSystem |
| Sub modules (common) | ESB/DSS projects. | <Project><ModuleName> |
StudentInformationSystemDataService |
| Folders | Custom folders that you create to categorize resources in registry resource projects. |
|
|
| Source files | Source files such as sequences and proxy services. | <FileName><Type>.<Extension> |
GetStudentSequence, SimpleStockQuoteProxyService |
Listed below are the best practices for working with the source code:
-
Follow a standard file naming convention to improve the readability of the code. Naming conventions change depending on the programming language.
-
Given below is the naming convention for WSO2 source files:
<ProjectName>_<FileName>_<FileType>.<Extension>Example:
Student_Student_Sequence.xml,Stocks_StockQuote_FileInbound.xmlYou can use a general naming convention for other known source files. If applicable, you can use a class naming convention that includes the business domain so that it is self explanatory. For example,
BubbleSortMediator.java. For more information on naming conventions, see the library article WSO2 Developer Studio - Development and Deployment Best Practices.
Using mediators¶
Using the Log mediator¶
- When a server encounters errors, you should have enough information about the errors in the logs.
- To log mediated messages, the best option is to use the Log mediator.
- In a production setup, it is not recommended to use the Log mediator within sequences and proxy services other than in the Fault sequences.
- Using logs with information such as ERROR_CODE is generally useful to understand the issue.
- Put the Log mediators within the Fault sequences, which capture information about errors.
- In the development phase, you should use Log mediators in the message flow as checkpoints.
- If you are using the Log mediator to track and troubleshoot the
message flow, set the log category to
DEBUG. - If you are in a development environment, ensure that you set the
global log level of
org.apache.synapse.mediators.builtin.LogMediatortoDEBUG. - If you are in a production environment, ensure that you set the
global log level of
org.apache.synapse.mediators.builtin.LogMediatorto INFO. Setting the log level to INFO allows you to troubleshoot the message flow in production whenever required without having to go through the synapse configuration. - You should use Log mediators in the
FaultSequenceto capture information about errors that occur. The logs entries printed via theFaultSequenceswill be available in the wso2carbon.log that is in the main log file.
Using the Class mediators¶
-
You should not write a Class mediator if the intended functionality can be achieved using the enterprise service bus capabilities of WSO2 Micro Integrator. Following this practice avoids maintenance overhead. If you want to see detailed information on the functionality of each built-in mediator of WSO2 Micro Integrator, see the Mediator catalog.
-
If you are writing a Class mediator, ensure that you have a good understanding of the performance impact and possible memory leaks so that you can take these into consideration.
-
Be sure to specify a proper package name for Class mediators
- Be sure to apply all java naming conventions and code best practices when you write the code for Class mediators.
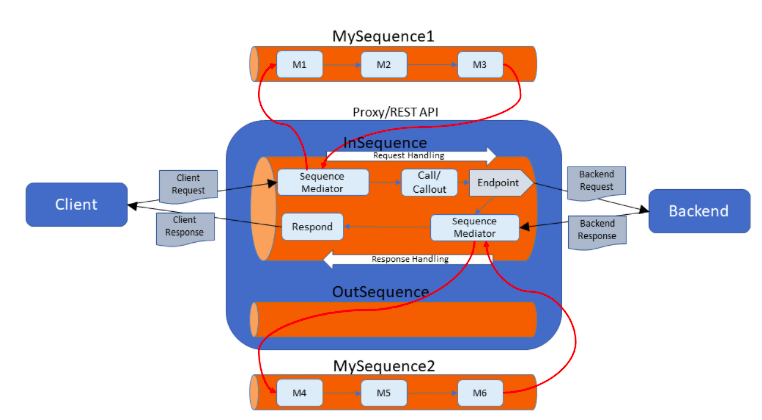
Using the Call vs. Callout vs. Send mediators¶
- You can use either the Call mediator, Callout mediator or Send mediator to send a message to an endpoint.
- If you use the Send mediator to send a message, the response goes to
the
OutSequence(or to the specified receiving sequence). - If you use the Call mediator to send a message, the response goes to the next mediator, which is placed right after the send mediator in the mediation flow.
- The use of Call mediator is recommended for service chaining scenarios.
- Both the Send mediator and Call mediator use the non blocking transport . Therefore, there is no difference between the performance of the Send and Call mediators.
-
Behaviour of the Callout mediator is similar to the Call mediator, but it uses the blocking transport to send the message out. Therefore , in terms of performance, Callout mediator is not as good as the Call mediator or Send mediator. If there are scenarios where blocking behaviour is required, you can use the Callout mediator. For example, see JMS Transactions .
Info
You should not use the Callout mediator unless there is a specific requirement for blocking behaviour in the underlying transport implementation.
Tip
The Callout mediator functionality has been merged into the Call mediator in WSO2 Micro Integrator. Therefore, you can use the Call mediator and set the blocking flag appropriately to switch between non-blocking and blocking behaviour.
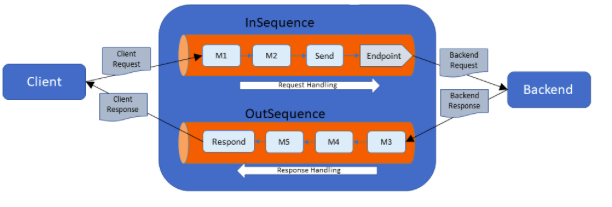
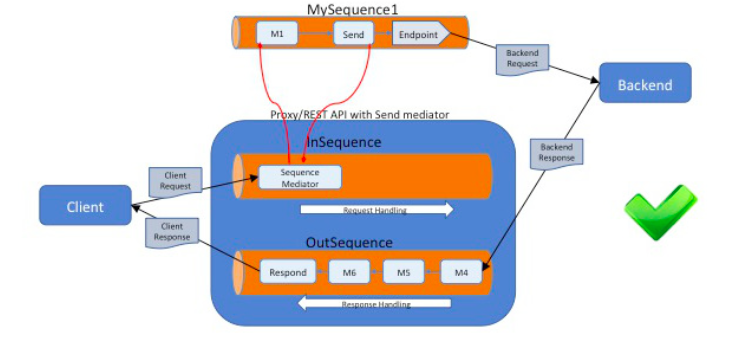
The following diagram illustrates a proxy/REST API with a Send mediator:
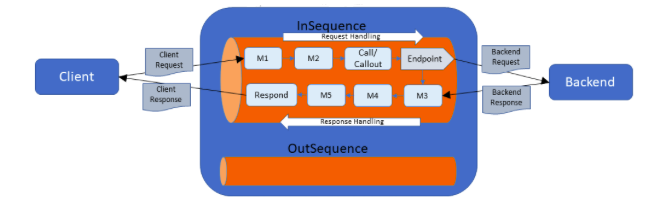
The following diagram illustrates a proxy/REST API with a Call/Callout mediator:
Using the ForEach mediator¶
Iterate Mediator is quite similar to the ForEach mediator. You can use complex XPath expressions to conditionally select elements to iterate over in both mediators. Following are the main difference between ForEach and Iterate mediators:
- Use the ForEach mediator only for message transformations. If you need to make back-end calls from each iteration, then use the iterate mediator.
- ForEach supports modifying the original payload. You can use Iterate for situations where you send the split messages to a target and collect them by an Aggregate in a different flow
- You need to always accompany an Iterate with an Aggregate mediator. ForEach loops over the sub-messages and merges them back to the same parent element of the message.
- In Iterate you need to send the split messages to an endpoint to continue the message flow. However, ForEach does not allow using Call , Send and Callout mediators in the sequence.
- ForEach does not split the message flow, unlike Iterate Mediator. It guarantees to execute in the same thread until all iterations are complete.
When you use ForEach mediator, you can only loop through segments of the message and do changes to a particular segment. For example, you can change the payload using payload factory mediator. But you cannot send the split message out to a service. Once you exit from the ForEach loop, it automatically aggregates the split segments. This replaces the ForEach function of the complex XSLT mediators using a ForEach mediator and a Payload Factory mediator. However, to implement the split-aggregate pattern, you still need to use Iterate mediator.
Using the Clone mediator¶
When using a Clone mediator, use a Call mediator in the target
sequence to bring the responses back into the In-Sequence. This
continues the mediation since the Continuation Stack gets pushed into
the Synapse Message Context via the handleMessage
method in the SynapseCallbackReceiver class.
Otherwise, the Continuation Stack becomes empty in the Synapse Message Context if you do not use a Call mediator in the target sequence.
Using the Loopback mediator¶
Do not include the Loopback mediator in the OutSequence .
Tip
When a message passes from the InSequence (request path) to the OutSequence (response path), you cannot use the Loopback mediator to move the message back to the OutSequence again.
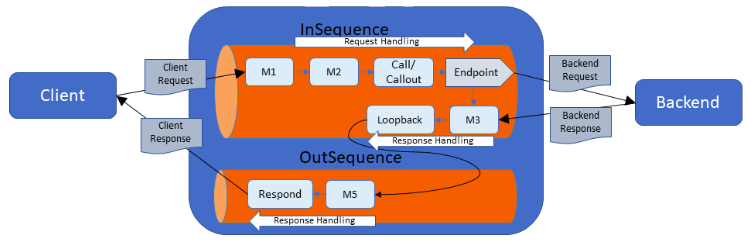
The following diagram illustrates a proxy/REST API with a Loopback mediator:
Using the Send mediator¶
-
You should not specify any mediator after the Send mediator or the Respond.
A message flow must end from these two mediators. Here, the message flow does not mean the current sequence. If you have these two mediators in a sub-sequence that gets called from a parent sequence, then once the message returns from the sub-sequence to the parent, the parent sequence should not include any mediator after the call to the sub-sequence. If you include a mediator after these two mediators, it can cause unusual behaviour in the message flow.
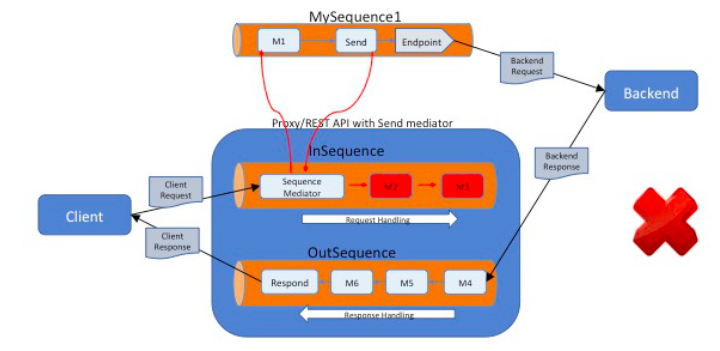
The following diagram illustrates an incorrect use of the Send mediator:
The following diagram illustrates the correct use of the Send mediator:
Mediators for message transformation¶
Follow the guidelines below to use mediators in scenarios that require message transformation:
- The most common message transformation use case is reconstructing the entire message payload according to the required format of the back end service. You can use the PayloadFactory Mediator to do the transformation in this use case, if you know that the structure of the new payload is simple, which means the message format is fixed, and only a few parameters are extracted from the original message.
- If the original message has repetitive segments and if you want to transform each of those segment into a new format with repetitive segments, you can use the For-Each Mediator together with the PayloadFactory mediator. The For-Each mediator iterates through the repetitive segments and the PayloadFactory mediator constructs the segments of the message to a new format. The combination of For-Each and PayloadFactory gives the functionality provided by the For-Each function in XSLT .
- If only a small part of the message needs to be modified (e.g., you need to add/remove an element) you should use the Enrich Mediator.
-
If the transformation logic is complex (i.e., the logic includes repetitive segments, conditional transformations, etc), you can use the XSLT Mediator to do the transformation.
Note
When you use the XSLT mediator, a third party engine does the message transformation. Therefore, this can impact the performance.
-
If you want to change the structure of the data in a message or convert and transform one data format to another, use the Data Mapper Mediator.
- If you want to work with large file transformations, use the Smooks Mediator.
General mediator best practices¶
- Use the Iterate mediator in association with the Aggregate mediator.
- Do not do any configuration after the Send mediator.
- Do proper error handling to handle mediation errors as well as endpoint errors.
- Use appropriate intervals for tasks.
- Use the ForEach mediator only for message transformations. If you need to make back-end calls from each iteration, then use the iterate mediator.
-
Do not use the DB mediators (DBReport and DBLookup ) with complex SQL queries or in scenarios where you need to simultaneously retrieve multiple rows. Instead, use the data services functionality of WSO2 Micro Integrator.
-
Use dollar context (i.e., $ctx) instead of get-property() . This is because the get - property methods search even in Registry if the value is not available in the message context. Thus, it affects performance as Registry search is an expensive operation. However,
$ctxonly checks in the message context.
If you need to retrieve a property that you have set on a message, use the predefined XPath variables such as $ctx instead of the get-property() function for better performance. For example, use$ctx:proxy.name instead ofget-property('proxy.name').
For more information on the predefined XPath variables that you can use to retrieve a property, and for examples of XPath variable usage, see Synapse XPath Variables.Note
The use of the
get-property()function can have a lower performance because it does a registry lookup when the value is not available in the message context. Therefore, the recommended approach is to use predefined XPath variables when you need to retrieve a property. You will encounter this performance issue only if you are using WSO2 ESB 4.9.0 or below. -
Reusing a defined sequence
If you want to repeatedly use the same mediation sequence, you can define it and save it either in the Synapse configuration or in the Registry, with a unique name. Then you can call the mediation sequence from the main sequence as well as from multiple proxy services and REST APIs. The saved sequence can be called via the Sequence mediator or can be selected as theInSequence,OutSequence, orFaultSequencewhen you define a proxy service or a REST API.The following diagram illustrates how a saved sequence can be called using the Sequence mediator:
When you are adding the last mediator in a sequence, make sure to use one of the following mediators depending on the scenario. Any mediator added after one of the following mediators will not be applied.
-
Use the Respond mediator as the last mediator if you want the message to be sent back to the client.
-
Use the Send Mediator as the last mediator if you want the message to be sent to a specific endpoint. If you want to mediate the message after it is sent, you can use the Clone mediator to make two copies of the message and process them separately in order to avoid conflicts.
-
Use the Drop mediator as the last mediator if you want to stop the mediation flow at a particular point (e.g., when a filter condition is not met).
-
Use the Loopback mediator as the last mediator if you want the message to be moved from the
InSequenceto theOutSequence.Info
The Loopback mediator prevents the execution of subsequent mediators in the
InSequence. -
Use the Store mediator as the last mediator if you want to enqueue messages to a message store.
Working with proxy services¶
Use REST APIs instead of proxy services for RESTful service development.
Configure FaultSequences
appropriately. For more information on how the
FaultSequence works, see the section on Handling errors.
Working with APIs¶
The following are some best practices to keep in mind when designing your APIs for use with REST.
- Use meaningful resource names to clarify what a given request does. A RESTful URI should refer to a resource that is a thing instead of an action. The name and structure of URIs should convey meaning to those consumers.
- Use plurals in node names to keep your API URIs consistent across all HTTP methods.
- Use HTTP methods appropriately . Use
POST,GET,PUT,DELETE,OPTIONSandHEADin requests to clarify the purpose of the request. ThePOST,GET,PUTandDELETEmethods map to the CRUD methods Create, Read, Update, and Delete, respectively. Each resource should have at least one method. - Create at most only one default resource (a resource with neither a uri-template nor a url-mapping) for each API.
- Offer both XML and JSON whenever possible.
- Use abstraction when it's helpful . The API implementation does not need to mimic the underlying implementation.
- Implement resource discoverability through links (HATEOAS) . As mentioned in the previous section, the application state should be communicated via hypertext. The API should be usable and understandable given an initial URI without prior knowledge or out-of-band information.
- Version your APIs as early as possible in the development cycle. At present, the ESB profile identifies each API by its unique context name. If you introduce a version in the API context (e.g., /Service/1.0.0), you can update it when you upgrade the same API (e.g., /Service/1.0.1).
- Secure your services using OAuth2, OpenID, or another authentication/authorization mechanism. See also Securing APIs.
Working with endpoints¶
-
Do not use anonymous endpoints. Always use named endpoints. As anynymous endpoints have auto-generated names in the synapse configuration, it is difficult to identify which endpoint is causing the error in case of an error.
-
Configure timeout settings appropriately. Timeout configurations are required before you go into production with the system.
The diagram below illustrates the typical message flow when a proxy service is involved in a client-server communication. The two connectores,
Client to Proxy connectionandProxy to Backend connection, a re two separate connections that do not depend on each other. Even if one connections times out, the other is unaffected.
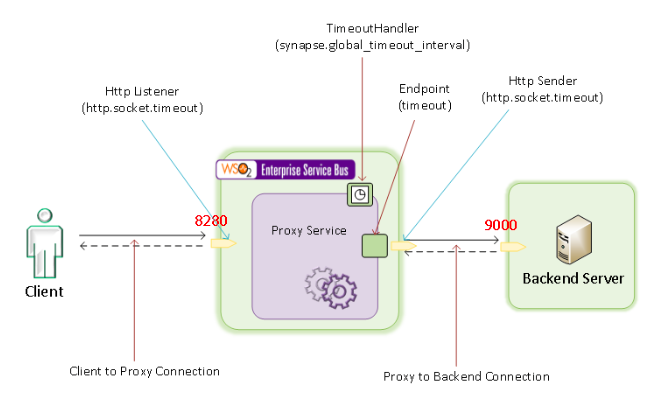
Here are the important timeout parameters you should configure before going into production:Parameter Description Configuration File Default Value Recommended Value [transport.http] socket_timeout = 180000The socket timeout of the Passthrough http/https transport sender and listener. You can find the passthru-http.properties file in the <EI_HOME>/confdirectory.deployment.toml180000 180000 Endpoint timeout The timeout parameter that you should configure at the endpoint level. You can configure timeout values as required for specific endpoints.
Here's a sample endpoint configuration that is configured with timeout parameters. Here,
<duration>is the timeout value, and<responseAction>is the action to be taken on timeout. In this example, it is invoking theFaultSequence.Follow the formula
Socket Timeout > max(Global endpoint timeout, Timeout of individual endpoints), and make sure that you set thehttp.socket.timeoutto a value higher than all other endpoint timeout values.Endpoint configuration files synapse.global_timeout_interval Depends on the use case, Typically 120000 [mediation] synapse.global_timeout_interval = "120000"Global timeout value for endpoints. Can be overwritten by individual endpoint timeout values.
Synapse, which is the underlying mediation engine of WSO2 Micro Integrator, is a complete asynchronous messaging engine that does not block its worker threads on network I/O. Instead, it registers a call-back for a particular request and returns the threads without waiting for a response. When a response is available, the registered call-back is used to correlate it with the relevant request so that further processing can be done.
If the backend server does not respond, it is required to clear the registered call-backs after a particular duration to prevent possible memory leaks. This duration is set via a timer task calledTimeoutHandler. Thesynapse.global_timeout_intervalparameter represents the duration that a call-back should be kept in the call-back store.If you have configured a timeout value at the endpoint level, the global timeout value is not taken into consideration for that endpoint. For all the other endpoints that do not have a timeout value configured, the global value is considered as the timeout value.
You can configure the
synapse.global_timeout_intervalparameter in the<MI_HOME>/conf/deployment.tomlfile. The default value is 120 seconds. If you want to support endpoint timeout values that are greater than 120 seconds, set thesynapse.global_timeout_intervalto a value more than 120 seconds. However, the need to set such large timeout values for endpoints is extremely unlikely.deployment.toml120000 120000 [synapse_properties] synapse.timeout_handler_interval = "15000"Duration between two TimeoutHandlerexecutions.TheTimeoutHandleris executed every 15 seconds by default. Therefore, the time that call-backs get cleared can deviate up to 15 seconds from the configured value.
You can configure theTimeoutHandlerexecution interval by specifying a required value forsynapse.timeout_handler_intervalin the<MI_HOME>/conf/deployment.tomlfile.deployment.toml15000 15000 -
Set the socket timeout value and individual endpoint timeout values appropriately. Use this formula to set timeout values:
Socket Timeout > max(Globalendpointtimeout, Timeoutofindividualendpoints) -
Be sure to set proper values to advanced configuration parameters, although they are optional.
The happy path should work with the default values, but you might encounter issues in production when the system does not follow the happy path. For example, if you use the default configurations and as an error occurs in your sequence, the endpoint gets suspended immediately and subsequent messages to that endpoint get rejected without being sent to the backend service. This might not be the expected behaviour in every use case. Therefore, it is important to perform endpoint error handling based on the use case. -
Use the HTTP endpoint for RESTful service invocations. The HTTP endpoint is especially designed to make RESTful service integration easy. For example, it supports
url-templates, which is an option to set the http method. -
For RESTful service integration, use either REST APIs or HTTP endpoints. You can use REST APIs to expose an integration solution as a RESTful service, and use HTTP endpoints to logically represent a RESTful backend service.
Error handling¶
Behaviour of the FaultSequence¶
-
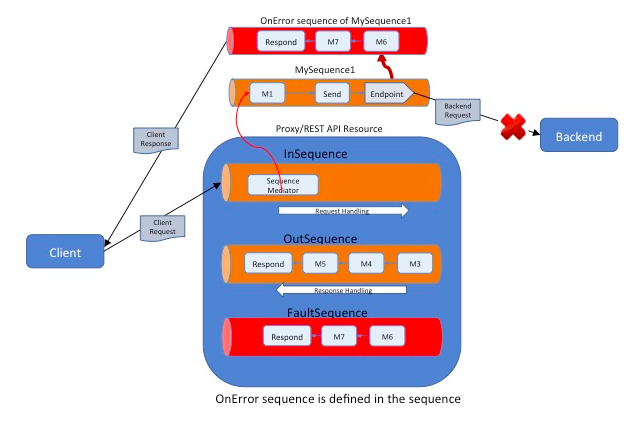
If a sequence explicitly defines a fault handler using the onError attribute, WSO2 Micro Integrator invokes that specific onError sequence whenever an error occurs in the sequence. This is true even if the sequence is invoked by a proxy service or in an API.
-
If a request arrives via the main sequence and fails within a sequence that does not explicitly define a fault handler, the default
FaultSequenceis invoked.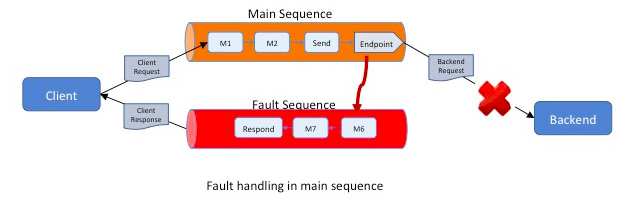 - If a request arrives via a proxy service or an API, and fails within
a sequence that does not explicitly define a fault handler, the
- If a request arrives via a proxy service or an API, and fails within
a sequence that does not explicitly define a fault handler, the
FaultSequenceof the proxy service is invoked.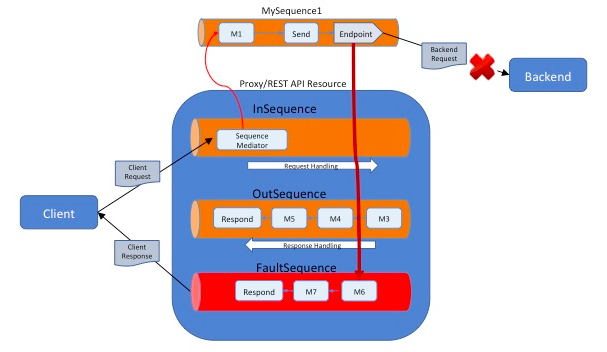 - If the proxy service does not have a
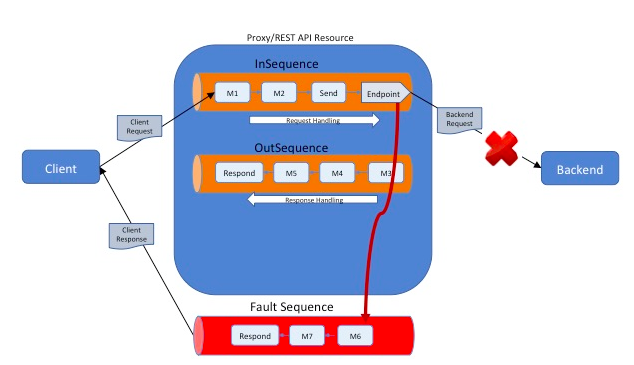
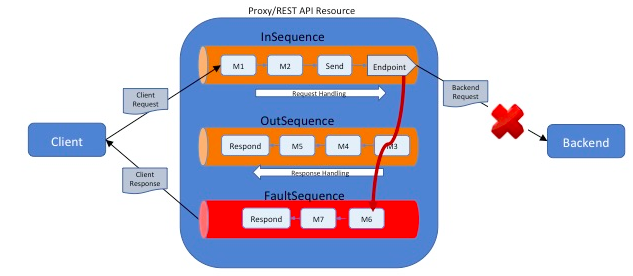
- If the proxy service does not have a
FaultSequencedefined, the default fault handler sequence is invoked.Tip
This is only applicable to WSO2 ESB 4.9.0 and above.
-
If there is a
FaultSequencedefined at the proxy service-level, and the onError sequence is referenced in theInSequence/OutSequence, then the onError sequence of the relevantInSequence/OutSequenceis invoked in the event of an error. In this case the proxy serviceFaultSequenceis ignored. -
If you send a request to a REST API, and there is no matching resource defined in the API for the request (i.e., REST API resource mismatch), an HTTP status code 200 is returned. You should define a default error sequence called
_resource_mismatch_handler_to handle such requests.
Best practices¶
- Whenever an error occurs in WSO2 Micro Integrator, the
mediation engine attempts to provide as much information as possible
about the
error. This is done by initializing a set of property values on the
erroneous message. Following are the properties:
- ERROR_CODE
- ERROR_MESSAGE
- ERROR_DETAIL
- ERROR_EXCEPTION
The above properties can be logged using the log mediator as follows
inside a FaultSequence path.
<log level="custom">
<property name="text" value="An unexpected error occurred"/>
<property name="message" expression="$ctx:ERROR_MESSAGE"/>
<property name="code" expression="$ctx:ERROR_CODE"/>
<property name="detail" expression="$ctx:ERROR_DETAIL"/>
<property name="exception" expression="$ctx:ERROR_EXCEPTION"/>
</log>- When you use the above properties, be sure to log the sequence name and proxy service/API name as well if you want to make debugging issues easier.
- If the configuration is complex, you need to separate the configuration into multiple sequences. When the configuration is separated into multiple sequences, you need to define an [error handler onError sequence in each sequence.
Troubleshooting¶
For a complete guide on troubleshooting issues that you may come across when working with enterprise service bus capabilities, see the Enterprise Service Bus Troubleshoot Guide . For troubleshooting with tooling, see Troubleshooting WSO2 Integration Studio.
Testing¶
- Define a test strategy to plan what should be tested in a specific project.
- Create a test plan covering all functional scenarios and performance tests.
- Write Jmeter, SoapUI test cases. If applicable always write automation tests.
- Write java integration tests whenever applicable to automate the test scenarios.
- Automate web application testing using Selenium.
- If you have an integration solution, isolate test scenarios of each product as much as possible and test the scenarios as separate units. Then you can write integration tests for the integration scenarios including one or more products using java tools such as Jmeter and Soap UI.
- For an application development project, you should perform tests throughout the Software Development Life Cycle (SDLC). Make sure that your testing environment is identical to the production environment when you execute test plans. (For example, resource allocation, VM sizes, VMs used for DBs, DB performance tuning, network resources etc in the production environment should be identical in the test environment)
- Do not rely on test results of a single node test.
- Test all custom solutions and artifacts that you develop. Never use default ports of the servers when testing custom features.
- Before you move into production, run load tests on the development and test environments using samples that replicate the production use case.
- Before you move into production, run a penetration test on the production setup. You need to suggest this to the customer and make arrangements for it beforehand.
- Run a round of User Acceptance Tests (UAT) against the requirements to ensure that the system satisfies the customer's acceptance criteria.
-
Document all functional test results and performance test results. Create a document explaining the steps followed, samples used, and the outcome of the tests for both functional test results as well as performance test results. Create a separate document including the summary of all the test results (e.g number of test cases that you executed, observations, summary etc).
Following is a sample template for functional test results:Test Case ID Function Description
Test Steps
Expected Results
Actual Results
Status
Comments
Following is a sample template for performance test results:
Test Case ID Function Description
Test Steps
Expected Results
Actual Results
Duration
CPU Usage
Memory Usage
Status
Comments
-
Never test on a single node.
- Conduct proper developer tests.
- Test use cases with all possible scenarios.
- It is not sufficient to test only the happy path.
- Do performance tests.
Deployment¶
General guidelines¶
- Ensure that you tune the deployment environment based on the performance tuning guidelines.
-
Install all patches using WSO2 Update Manager(WUM) in all environments.
Info
If you are using WSO2 ESB 4.9.0 or above, ensure that you have all WUM updates installed at any given time.
-
Pre-test patches in a test environment before going into the production environment. You should use an automated test suite to do this. For example, you can use JMeter Automation or SOAP UI .
- Pre-test artifacts in a test environment before deploying into the production environment.
- Pre-test configuration changes before applying them in the production environment.
- Automate the process of change deployment. You can use puppet for this purpose. For more information, see the tutorial on How To Use WSO2 Puppet Modules to Deploy WSO2 Products .
- Make sure you follow the production hardening guidelines before going into production or exposing instances to live traffic.
- To port your artifacts from one environment to another, first package the artifacts into a Composite Application (C-App) archive using WSO2 Integration, and then deploy the C-App in the new environment.
- It is not recommended to run more than one server instance inside a docker container.