Scalable Deployment¶
Scalable high availability deployment predominantly focuses on scaling the system according to the load or the TPS of the system. This is achieved with the help of horizontal scalability.
WSO2 Streaming Integrator uses Siddhi as the streaming language. Siddhi allows you to write Siddhi logic in a stateless way as well as a stateful way.
Stateless operations include filters, database operations etc., and stateful operations include window operations, aggregations etc., that keep data in memory to carry out calculations.
The deployment options for a scalable streaming integrator depends on the statelessness and the statefulness of Siddhi applications.
The following topics provide detailed descriptions of two approaches.
System Requirements
For system requirements for this deployment, see Installing the Streaming Integrator in a Virtual Machine.
Stateless scalable high availability (HA) deployment¶
In stateless scenarios, the system does not work with any in-memory state. Thus in order to scale, you can keep adding Streaming Integrator servers to the system and front them with a load balancer that publishes the events in round robin manner.
This is depicted in the diagram below.
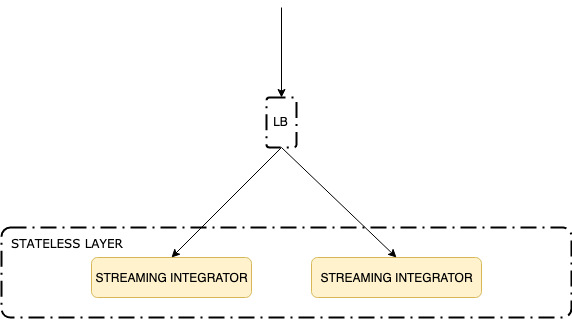
Stateful scalable high availability (HA) deployment¶
As described before, stateful operations keep state data in memory. Therefore, in order to scale such a system, you need to process specific data on the same node without processing same-state data in different servers. You can achieve this via data partitioning where one bucket of partitioned data is processed only in one specific server.
Info
In order to scale stateful operations, it is required to have some partitioning attribute available enabling the partitioned data to be processed independently.
The following is a high level diagram of event flow and components to achieve scalable, stateful, and highly available deployment.
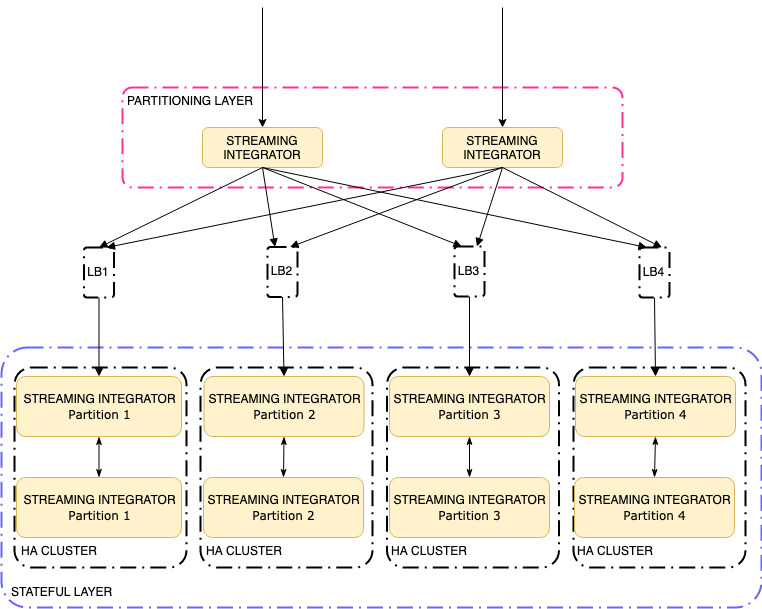
The following sections describe each component in detail and how to configure them with WSO2 Streaming Integrator.
Partitioning layer¶
As shown in the above diagram, first you need to have a partitioning layer. Here, you are using an SI server to achieve it. The function of this layer is to consume events from output sources and then partition the events based on a partitioning condition.
In order to partition you can leverage on the Distributed sink extension in WSO2 Streaming Integrator. The following is a sample Siddhi application syntax that defines a stream. It shows how the distributed sink can be applied to partition data. In this example, data is partitioned from tenant domain. For more information, see Siddhi Query Guide - Distributed Sink.
Note
In the following example, the definition of the Request stream(Request stream) only includes the logicto send events out for load balancers via http for each
partition. In addition, there should be a logic to consume eventsfrom outside and direct them to the Request stream.
e.g.,
// Stream defined with distributed sink with partitioned stratergy
@Sink(type = 'http',
@map(type='json'),
@distribution(strategy='partitioned', partitionKey='userTenantDomain',
@destination(publisher.url='http://Ip1:8009/Request'),
@destination(publisher.url='http://Ip2:8009/Request')))
define stream Request (meta_clientType string,
applicationConsumerKey string,
applicationName string,
applicationId string,
applicationOwner string,
apiContext string,
apiName string,
apiVersion string,
apiCreator string,,
apiTier string,
apiHostname string,
username string,
userTenantDomain string,,
requestTimestamp long,
throttledOut bool,
responseTime long,
backendTime long);According to above distributed sink configuration, events that arrive at the Request stream are partitioned based on the
userTenantDomain attribute. Therefore, if there are two tenant domain values fooDomain and barDomain, then events of
fooDomain can be published to Ip1, and the events of barDomain can be published to Ip2. The distributed sink ensures that the unique partitioned events are not distributed across the cluster. Here, Ip1 and Ip2 represent the load balancer
IPs. The reason for using load balancers is because the stateful layer also contains two SI servers to handle the high availability. Therefore, you need a load balancer to direct the traffic in a failover manner.
According to the above diagram, there are four partitions. Therefore, four load balancers are used.
You need the high availability in the partitioning layer. Therefore, you can use two WSO2 Streaming Integrator servers (minimum) as depicted in the diagram.
Stateful Layer¶
The function of this layer is to consume events according to each partition and carry out the rest of the stateful operations. When you have partitioned the date, you can seamlessly handle the scalability of the system as well as address the requirement for high availability of the system. Thus for each partition we can deploy the system as mentioned in two node minimum high available deployment section. Basically for each partition or partitions there will be a separate cluster of two SI nodes. So if active node fails for a particular partition the other node in the cluster will carry out the work.
In order to configure the stateful layer you can follow the minimum high availability deployment guide. The only difference in configurations regarding this layer would be , as mentioned since we maintain separate clusters for each partition the Cluster Configuration group id should be different for each cluster.
Sample cluster configuration can be as below :
- cluster.config:
enabled: true
groupId: group 1
coordinationStrategyClass: org.wso2.carbon.cluster.coordinator.rdbms.RDBMSCoordinationStrategy
strategyConfig:
datasource: WSO2_CLUSTER_DB
heartbeatInterval: 5000
heartbeatMaxRetry: 5
eventPollingInterval: 5000