Summarizing Data¶
Summarizing data refers to obtaining aggregates in an incremental manner for a specified set of time periods.
Performing clock-time based summarization¶
Performing clock time-based summarizations involve two steps:
-
Calculating the aggregations for the selected time granularities and storing the results.
-
Retrieving previously calculated aggregations for selected time granularities.
Calculating the aggregations for the selected time granularities and storing the results¶
To understand this, consider a scenario where the production statistics generated by the Sweet Production Factory processed. The results need to be summarized for different time granularities and saved so that they can be later retrieved for periodical production analysis. To do this, you can create a Siddhi application as shown below.
@App:name('ProductionAggregatesApp')
define stream ProductionStream (name string, amount double, timestamp long);
@store(type='rdbms', jdbc.url="jdbc:mysql://localhost:3306/Production", username="root", password="root" , jdbc.driver.name="com.mysql.jdbc.Driver")
define aggregation ProductionAggregation
from ProductionStream
select name, amount, sum(amount) as total, avg(amount) as average
group by name
aggregate by timestamp every sec ... year;-
The stream
In addition to the
nameandamountattributes to capture the name of the product and the amount produced, the stream has an attribute namedtimestampto capture the time at which the production run takes place. he aggregations are executed based on this time. This attribute's value could either be a long value (reflecting the Unix timestamp in milliseconds), or a string value adhering to one of the following formats:-
<YYYY>-<MM>-<dd> <HH>:<mm>:<ss> <Z>: This format can be used if the timezone needs to be specified explicitly. Here the ISO 8601 UTC offset must be provided. e.g., +05:30 reflects the India Time Zone. If time is not in GMT, this value must be provided. -
<yyyy>-<MM>-<dd> <HH>:<mm>:<ss>: This format can be used if the timezone is in GMT.
-
-
The aggregation
You are defining the
ProductionAggregationaggregation to store the aggregated values.A store is connected to it via the
@storeannotation. If the store definition is not provided, the data is stored in-memory. The aggregations stored in-memory can be lost when the Siddhi application is stopped. -
Siddhi query
The Siddhi query gets the production events from the
ProductionStreamstream, calculates the total and the average, and aggregates them everysec...year. This means the production total and the average is calculated per second, per minute, per hour, per day, per month, and per year.
Retrieving previously calculated aggregations for selected time granularities¶
To retrieve the aggregates stored via the Siddhi application in the previous section, you need to create a new stream for data retrieval and join it with the aggregation that you previously created. In this example, let's assume that you need to production statistics for the period 12th October 2020 to 16th October 2020.
For this, you can update the ProductionAggregatesApp Siddhi application that you previously created as follows:
-
Define a stream in which you want to generate the event (request) to retrieve data as follows.
define stream ProductionSummaryRetrievalStream (name string); -
Define a query that specifies the criteria for retrieving data as follows.
Observe the following in the above Siddhi query:@info(name = 'RetrievingAggregates') from ProductionSummaryRetrievalStream as b join ProductionAggregation as a on a.name == b.name within "2020-10-12 00:00:00 +00:00", "2020-10-17 00:00:00 +00:00" per "days" select a.name, a.total, a.average insert into ProductionSummaryStream;-
The join
The above query joins the
ProductionsSummaryRetyrievalStreamstream and theProductionAggregationaggregation. TheProductionsSummaryRetyrievalStreamstream is assignedbas the short name, and the aggregation is assigneda. Therefore,a.name == b.namespecifies that a matching event is identified when the value for thenameattribute is the same.For more information about how to perform joins, see Enriching Data.
-
withinclauseThis specifies the time interval for which the aggregates should be retrieved. You are requesting data for the period between 00.00 AM of 12th October 2020 and 00.00 AM of 17th October 2020 so that the days 12th, 13th, 14th, 15th, and the 16th of October are covered.
-
perclauseThis specifies that the aggregates should be summarized per day.
-
selectclauseThis selects the
name,totalandaverageattributes to be selected from the aggregate to be included in the output event.
The output event is inserted into the
ProductionSummaryStreamstream. -
Try it out¶
To try out the example given above, follow the procedure below:
-
Download and install MySQL. Then start the MySQL server and create a new database in it by issuing the following command:
CREATE SCHEMA production;Then open the
<SI_TOOLING_HOME>/conf/server/deployment.yamlfile and add the following datasource configuration underdatasources.- name: Production_DB description: The datasource used for Production Statistics jndiConfig: name: jdbc/production definition: type: RDBMS configuration: jdbcUrl: 'jdbc:mysql://localhost:3306/production?useSSL=false' username: root password: root driverClassName: com.mysql.jdbc.Driver minIdle: 5 maxPoolSize: 50 idleTimeout: 60000 connectionTestQuery: SELECT 1 validationTimeout: 30000 isAutoCommit: false -
Open a new file in Streaming Integrator Tooling. Then add and save the following Siddhi application.
@App:name('ProductionAggregatesApp') @App:description('Description of the plan') define stream ProductionStream (name string, amount double, timestamp long); define stream ProductionSummaryRetrievalStream (name string); @sink(type = 'log', prefix = "Production Summary", @map(type = 'text')) define stream ProductionSummaryStream (name string, total double, average double); @store(type = 'rdbms', jdbc.url = "jdbc:mysql://localhost:3306/production?useSSL=false", username = "root", password = "root", jdbc.driver.name = "com.mysql.jdbc.Driver") define aggregation ProductionAggregation from ProductionStream select name, amount, sum(amount) as total, avg(amount) as average aggregate by timestamp every seconds...years; @info(name = 'RetrievingAggregates') from ProductionSummaryRetrievalStream as b join ProductionAggregation as a on a.name == b.name within "2020-10-12 00:00:00 +00:00", "2020-10-17 00:00:00 +00:00" per "days" select a.name as name, a.total as total, a.average as average insert into ProductionSummaryStream;
This is the complete ProductionAggregatesApp Siddhi application with the queries given in the examples to store and retrieve aggregates. You are annotating a sink of the log type to the ProductionSummaryStream stream to which the retrieved aggregates are sent so that you can view the retrieved information in the terminal logs.
-
To store aggregates, simulate five events with the following values for the
ProductionStreamstream via the Event Simulator tool. For instructions to simulate events, see Testing Siddhi Applications.name amount timestamp brownie901602489419000brownie901602488519000eclairs951602661319000brownie1001602747719000brownie1201602834119000The above events are stored in the
productiondatabase that you previously defined. -
To retrieve the information you stored, simulate an event for the
ProductionSummaryRetrievalStreamstream withbrownieas the value for `name'. For instructions to simulate events, see Testing Siddhi Applications.The Streaming Integrator Tooling terminal displays the following logs.

Supported extensions¶
The following table describes the complete list of extensions that provide aggregation functionality when you perform time-based aggregations:
| Extension | Description |
|---|---|
| Siddhi-execution-math | Transforms data by performing mathematical operations. |
| Siddhi-execution-streeamingml | Provides streaming machine learning (clustering, classification and regression) for event streams. |
Performing short term summarizations¶
This section explains how to apply Siddhi logic to process a subset of events received to a stream based on time or the number of events. This is achieved via Siddi Windows. The window can apply to a batch of events or in a sliding manner.
The following are a few examples of how short time summarizations can be performed based on time or the number of events.
-
Performing a time-based summarization in a sliding manner
This involves selecting a subset of events based on a specified duration of time in a sliding manner as illustrated via an example in the diagram below.
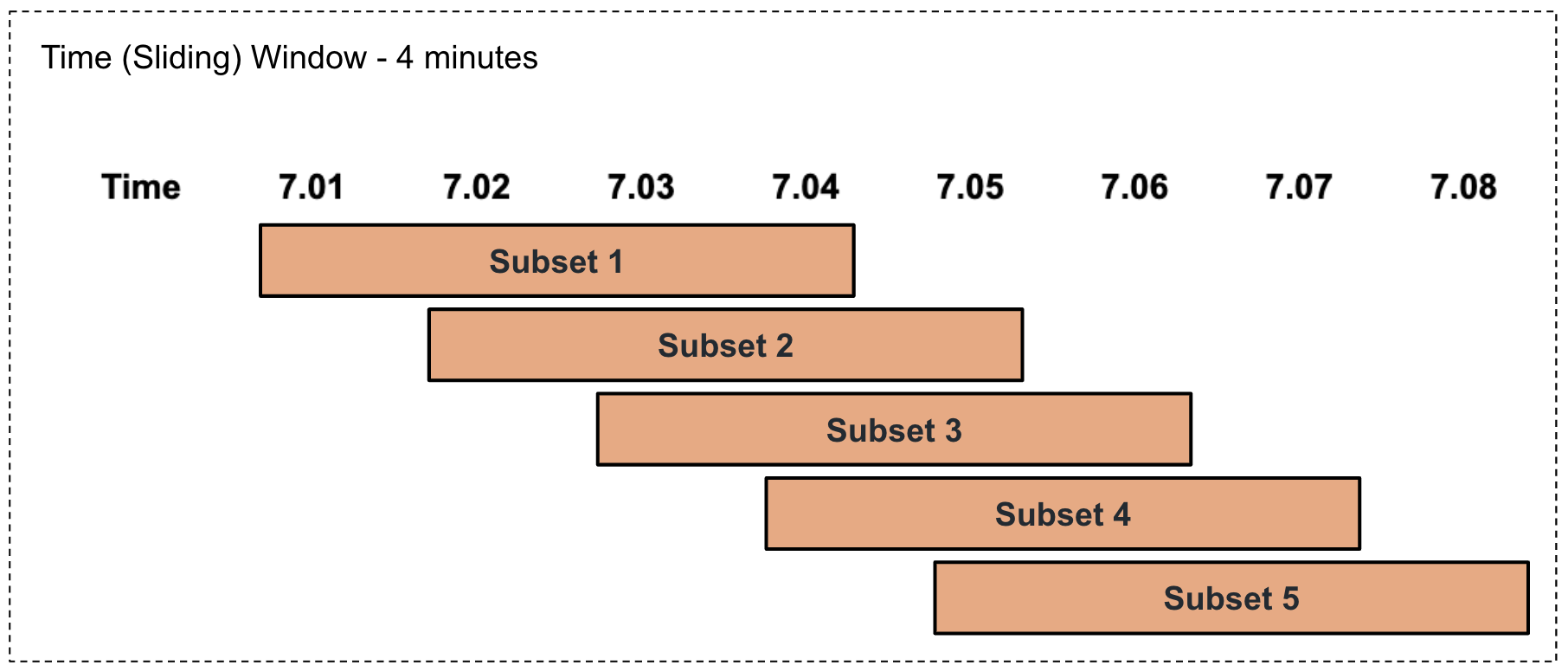
For example, consider that the factory foreman of a sweet factory wants to calculate the production total and average per product every four minutes in a sliding manner. To address this, you can write a query as follows.
Here,from ProductionStream#window.time(4 min) select name, sum(amount) as pastFourMinTotal, avg(amount) as pastFourMinAvg group by name insert into TimeSlidingOutputStream;#window.time(4 min)represents a sliding time window of four minutes. Based on this, the total for the last four minutes is calculated and presented aspastFourMinTotal, and the average for the last four minutes is calculated and presented aspastFourMinAvg. -
Performing a time-based summarization in a tumbling manner
This involves selecting a subset of events based on a specified duration of time in a tumbling manner as illustrated via an example in the diagram below.
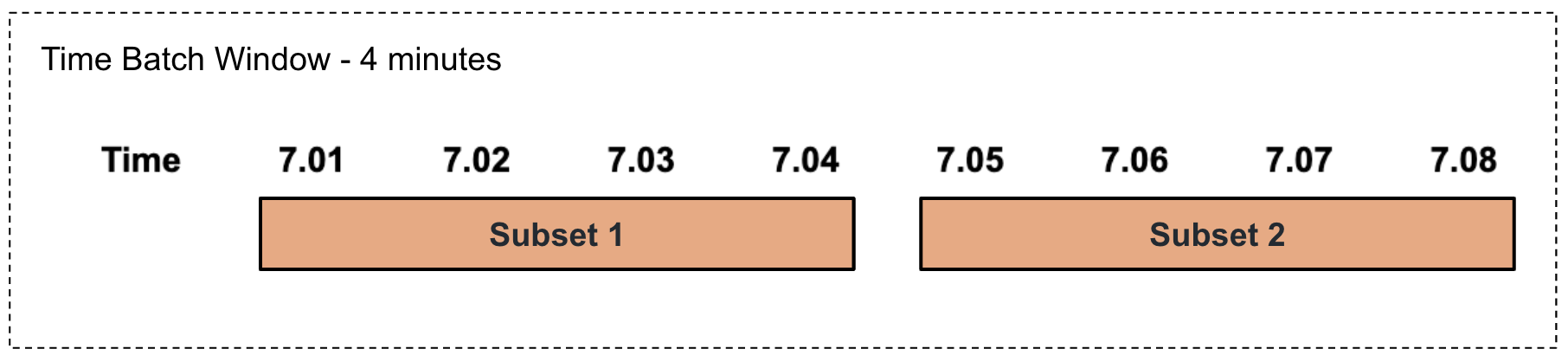
For example, consider that the factory foreman of a sweet factory wants to calculate the production total and average per product every four minutes in a tumbling manner. To address this, you can write a query as follows.
Here,from ProductionStream#window.timeBatch(4 min) select name, sum(amount) as pastFourMinTotal, avg(amount) as pastFourMinAvg group by name insert into TimeBatchOutputStream;#window.timeBatch(4 min)represents a tumbling time window of four minutes. Based on this, the total for the last four minutes is calculated and presented aspastFourMinTotal, and the average for the last four minutes is calculated and presented aspastFourMinAvg. -
Performing a length-based summarization in a sliding manner
This involves selecting a batch of events based on the number of events specified in a sliding manner as illustrated via an example in the diagram below.
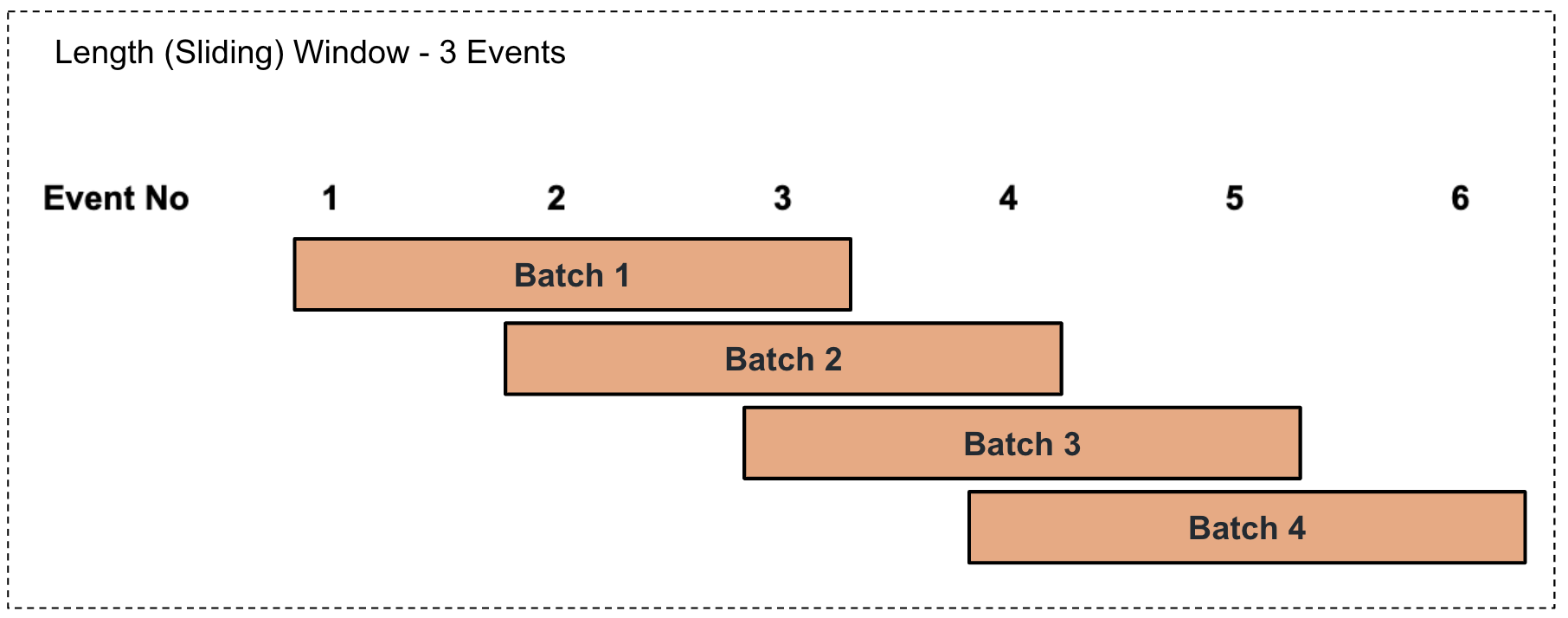
For example, consider that the factory foreman of a sweet factory wants to calculate the production total and average per product for every three events in a sliding manner. To address this, you can write a query as follows.
Here,from ProductionStream#window.length(3) select name, sum(amount) as lastBatchTotal, avg(amount) as lastBatchAvg group by name insert into LengthSlidingOutputStream;#window.length(3)represents a sliding length window of 3 events. Based on this, the total for the last three events is calculated and presented aslastBatchTotal, and the average for the last three events is calculated and presented aslastBatchAvg. -
Performing a length-based summarization to a batch of events
This involves selecting a batch of events based on the number of events specified in a sliding manner as illustrated via an example in the diagram below.
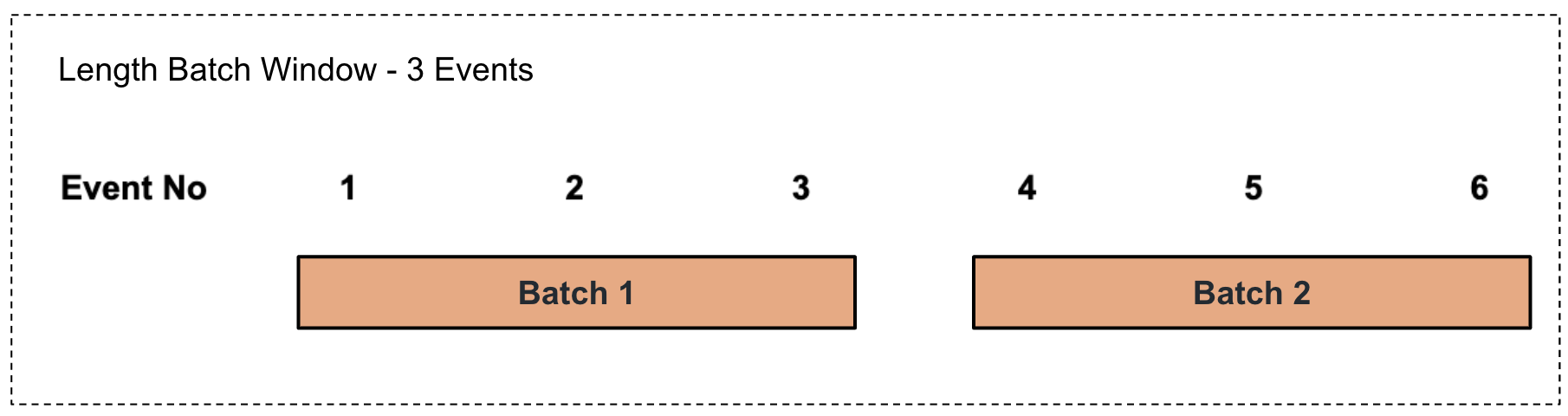
For example, consider that the factory foreman of a sweet factory wants to calculate the production total and average per product for every three events in a sliding manner. To address this, you can write a query as follows.
Here,from ProductionStream#window.lengthBatch(3) select name, sum(amount) as lastBatchTotal, avg(amount) as lastBatchAvg group by name insert into LengthBatchOutputStream;#window.lengthBatch(3)represents a sliding length window of 3 events. Based on this, the total for the last three events is calculated and presented aslastBatchTotal, and the average for the last three events is calculated and presented aslastBatchAvg.
Try it out¶
To try out the four sample queries given above, follow the steps below:
-
Open a new file. Then add and save the following Siddhi application.
@App:name('ProductionSummaryApp') @sink(type = 'log', prefix = "Four Minute Summary", @map(type = 'text')) define stream TimeSlidingOutputStream (name string, pastFourMinTotal double, pastFourMinAvg double); @sink(type = 'log', prefix = "Three Production Run Summary", @map(type = 'passThrough')) define stream LengthSlidingOutputStream (name string, lastBatchTotal double, lastBatchAvg double); define stream ProductionStream (name string, amount double, timestamp long); @sink(type = 'log', prefix = "Four Minute Summary - Batch", @map(type = 'text')) define stream TimeBatchOutputStream (name string, pastFourMinTotal double, pastFourMinAvg double); @sink(type = 'log', prefix = "Three Production Run Summary - Batch", @map(type = 'passThrough')) define stream LengthBatchOutputStream (name string, lastBatchTotal double, lastBatchAvg double); @info(name = 'query1') from ProductionStream#window.time(4 min) select name, sum(amount) as pastFourMinTotal, avg(amount) as pastFourMinAvg group by name insert into TimeSlidingOutputStream; @info(name = 'query2') from ProductionStream#window.timeBatch(4 min) select name, sum(amount) as pastFourMinTotal, avg(amount) as pastFourMinAvg group by name insert into TimeBatchOutputStream; @info(name = 'query3') from ProductionStream#window.length(3) select name, sum(amount) as lastBatchTotal, avg(amount) as lastBatchAvg group by name insert into LengthSlidingOutputStream; @info(name = 'query4') from ProductionStream#window.lengthBatch(3) select name, sum(amount) as lastBatchTotal, avg(amount) as lastBatchAvg group by name insert into LengthBatchOutputStream;
The above Siddhi application has all four sample queries used as examples in this section. Those queries insert their output into four different output streams connected to log sinks to log the output of each query.
-
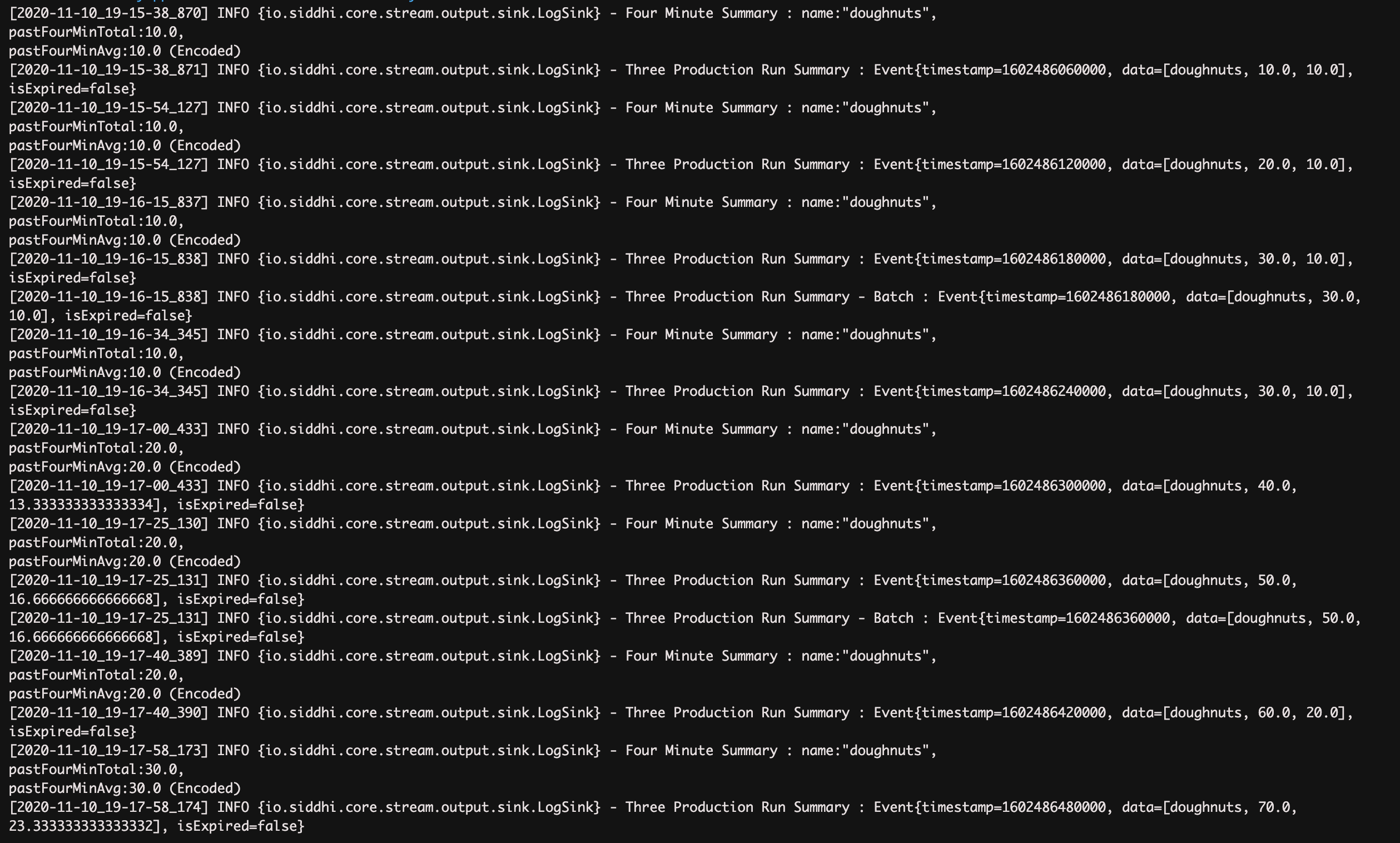
Simulate eight events for the
ProductionStreaminput stream of the above Siddhi application as follows. For instructions to simulate events, see Testing Siddhi Applications.name amount timestamp doughnuts101602486060000doughnuts101602486120000doughnuts101602486180000doughnuts101602486240000doughnuts201602486300000doughnuts201602486360000doughnuts201602486420000doughnuts301602486480000The above simulation results in the following logs.
Supported methods of summarization¶
WSO2 Streaming Integrator supports the following methods of summarization via Siddhi extensions. For more information about a summarization method, click on the relevant Siddhi link.
| Method (Window type) | Description |
|---|---|
| Deduplicate | Identifies duplicate events that arrive during a specified time interval and removes them. |
| ever | latest events based on a given unique keys. When a new event arrives with the same key it replaces the one that exist in the window. |
| externalTimeBatch | This is a batch (tumbling) time window that is determined based on an external time, i.e., time stamps that are specified via an attribute in the events. It holds the latest unique events that arrived during the last window time period. The unique events are determined based on the value for a specified unique key parameter. When a new event arrives within the time window with a value for the unique key parameter that is the same as that of an existing event in the window, the existing event expires and it is replaced by the new event. |
| first | This holds only the first set of unique events according to the unique key parameter. When a new event arrives with a key that is already in the window, that event is not processed by the window. |
| firstLengthBatch | This holds a specific number of unique events (depending on which events arrive first). The unique events are selected based on a specific parameter that is considered as the unique key. When a new event arrives with a value for the unique key parameter that matches the same of an existing event in the window, that event is not processed by the window. |
| firstTimeBatch | This holds the unique events according to the unique key parameters that have arrived within the time period of that window and gets updated for each such time window. When a new event arrives with a key which is already in the window, that event is not processed by the window. |
| length | This holds the events of the latest window length with the unique key and gets updated for the expiry and arrival of each event. When a new event arrives with the key that is already there in the window, then the previous event expires and new event is kept within the window. |
| lengthBatch | This holds a specified number of latest unique events. The unique events are determined based on the value for a specified unique key parameter. The window is updated for every window length, i.e., for the last set of events of the specified number in a tumbling manner. When a new event arrives within the window length and with the same value for the unique key parameter as an existing event in the window, the previous event is replaced by the new event. |
| time | This holds the latest unique events that arrived during the previous time window. The unique events are determined based on the value for a specified unique key parameter. The window is updated with the arrival and expiry of each event. When a new event that arrives within a window time period has the same value for the unique key parameter as an existing event in the window, the previous event is replaced by the new event. |
| timeBatch | This holds latest events based on a unique key parameter. If a new event that arrives within the time period of a window has a value for the key parameter which matches that of an existing event, the existing event expires and it is replaced by the latest event. |
| timeLengthBatch | This holds latest events based on a unique key parameter. The window tumbles upon the elapse of the time window, or when a number of unique events have arrived. If a new event that arrives within the period of the window has a value for the key parameter which matches the value of an existing event, the existing event expires and it is replaced by the new event. |