Performance Analysis Results¶
Notes
- These performance statistics were taken when the load average was below 3.8 in the 4 core instance.
- Most of the examples given below use log sinks to log statistics for performance monitoring purposes. However, note that log sinks incur a high system overhead and can lower performance by even more than 50%.
Performance analysis results summary¶
The recommended CPU and memory specifications for Docker containers are as follows:
-
CPU: 4 cores
-
Memory: 8GB
The recommended memory specifications SI server as follows. These are configured in the <SI_Home>/wso2/server/bin/carbon.sh file.
-
Xms: 2GB
-
Xmx: 4GB
The exact specifications used in the use cases listed in this section are summarised in the table below:
| Scenario | CPU | Memory | SI Memory Allocation | Input TPS | Input Message Size | Output TPS |
|---|---|---|---|---|---|---|
| Consuming events using Kafka source | 4 cores | 8GB | - Xms: 2g - Xmx: 4g |
180K | 60 bytes | Not Available |
| Consuming messages from an HTTP Source | 4 cores | 8GB | - Xms: 2g - Xmx: 4g |
30K | 60 bytes | Not Available |
| Sending HTTP requests and consuming the responses | 4 cores | 8GB | - Xms: 2g - Xmx: 4g |
29K | Sent: 60 bytes Received: 60 bytes |
- To HTTP Source: 29K - To HTTP Request Sink: 29K |
| Performing ETL tasks | 4 cores | 16GB | - Xms: 2g - Xmx: 4g |
29K | Read: 100 bytes Stored: 200 bytes |
To Oracle Store: 72K |
| Consuming messages from a Kafka source and publish to an HTTP endpoint | 2 cores | Docker Memory: 3GB | - Xms: 256m - Xmx: 1g |
10K | Consumed: 400 bytes Published: 600 bytes |
10K |
| Consuming messages from a CSV file and publish to a MySQL table | 4 cores | Docker Memory: 8GB | - Xms: 2g - Xmx: 4g |
9K | Read: 300 bytes Published: 300 bytes |
9K |
| Monitoring a database table in MySQL and publishing data to a Kafka topic | 4 cores | Docker Memory: 8GB | - Xms: 2g - Xmx: 4g |
13K | Read: 300 bytes Published: 300 bytes |
13K |
| Read XML file and mapping to a stream | 4 cores | Docker Memory: 8GB | - Xms: 2g - Xmx: 4g |
40K | read: 350 bytes | 40K |
| Reading an XML file and publishing to a Kafka topic | 4 cores | Docker Memory: 8GB | - Xms: 2g - Xmx: 4g |
38K | read: 350 bytes Published: 350 bytes |
38K |
Consuming events using Kafka source¶
Specifications of EC2 Instances¶
- Stream Processor : c5.xLarge
- Kafka server : c5.xLarge
- Kafka publisher : c5.xLarge
Siddhi Application¶
@App:name("HelloKafka")
@App:description('Consume events from a Kafka Topic and publish to a different Kafka Topic')
@source(type='kafka',
topic.list='kafka_topic',
partition.no.list='0',
threading.option='single.thread',
group.id="group",
bootstrap.servers='172.31.0.135:9092',
@map(type='json'))
define stream SweetProductionStream (name string, amount double);
@sink(type='log')
define stream KafkaSourceThroughputStream(count long);
from SweetProductionStream#window.timeBatch(5 sec)
select count(*)/5 as count
insert into KafkaSourceThroughputStream;Results¶
Average Consuming TPS from Kafka: 180K
Consuming messages from an HTTP Source¶
Specifications of EC2 Instances¶
- Stream Processor : c5.xLarge
- JMeter : c5.xLarge
Siddhi Application¶
@App:name("HttpSource")
@App:description('Consume events from http clients')
@source(type='http', worker.count='20', receiver.url='http://172.31.2.99:8081/service',
@map(type='json'))
define stream SweetProductionStream (name string, amount double);
@sink(type='log')
define stream HttpSourceThroughputStream(count long);
from SweetProductionStream#window.timeBatch(5 sec)
select count(*)/5 as count
insert into HttpSourceThroughputStream;Results¶
Average Consuming TPS from Http Source: 30K
Sending HTTP requests and consuming the responses¶
Specifications of EC2 Instances¶
- Stream Processor : c5.xLarge
- JMeter : c5.xLarge
- Web server : c5.xLarge
Siddhi Application¶
@App:name("HttpRequestResponse")
@App:description('Consume events from an HTTP source, ')
@source(type='http', worker.count='20', receiver.url='http://172.31.2.99:8081/service',
@map(type='json'))
define stream SweetProductionStream (name string, amount double);
@sink(type='http-request', l, sink.id='production-request', publisher.url='http://172.17.0.1:8688//netty_echo_server', @map(type='json'))
define stream HttpRequestStream (batchNumber double, lowTotal double);
@source(type='http-response' , sink.id='production-request', http.status.code='200',
@map(type='json'))
define stream HttpResponseStream(batchNumber double, lowTotal double);
@sink(type='log')
define stream FinalThroughputStream(count long);
@sink(type='log')
define stream InputThroughputStream(count long);
from SweetProductionStream
select 1D as batchNumber, 1200D as lowTotal
insert into HttpRequestStream;
from SweetProductionStream#window.timeBatch(5 sec)
select count(*)/5 as count
insert into InputThroughputStream;
from HttpResponseStream#window.timeBatch(5 sec)
select count(*)/5 as count
insert into FinalThroughputStream;Results¶
- Average Consuming TPS to HTTP Source : 29K
- Average Publishing TPS from HTTP request sink : 29K
- Average Consuming TPS from HTTP response source: 29K
Performing ETL tasks¶
Specifications of EC2 Instances¶
- Stream Processor : m4.xlarge
- JMeter : m4.xlarge
- Web server : m4.xlarge
Siddhi Application¶
This scenario was tested using two Siddhi applications that execute the process explained below.
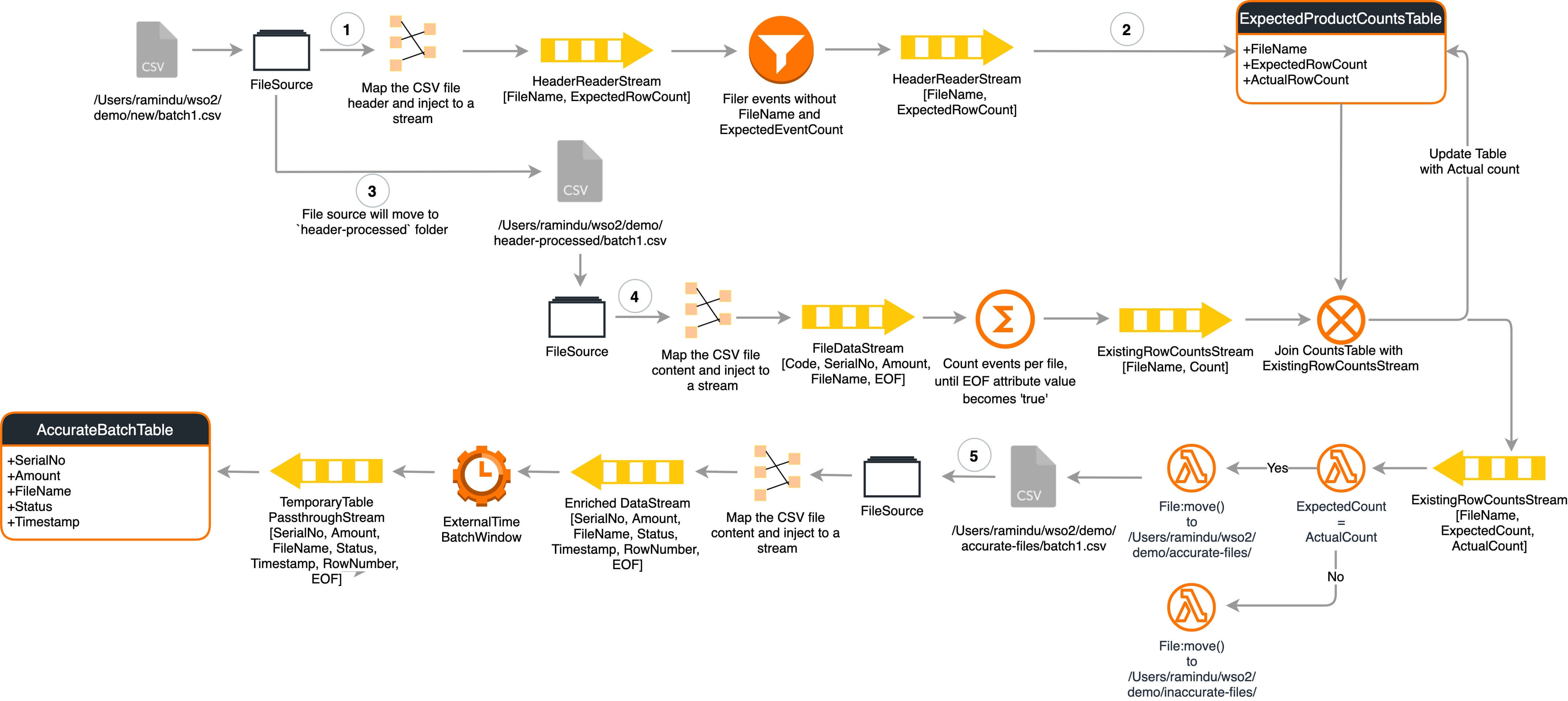
The two Siddhi applications are as follows:
ETLFIleRecordsCopier.siddhi
@App:name('ETLFileRecordsCopier')
@App:description('This sample demonstrates on integrating a File in a particular location with a Database.')
@source(type='file', mode='LINE',
dir.uri='file:/Users/wso2/demo/accurate-files',
action.after.process='MOVE',
move.after.process='file:/Users/wso2/demo/moved',
tailing='false',
header.present='true',
@map(
type='csv',
delimiter='|',
@attributes(code = '0', serialNo = '1', amount = '2', fileName = 'trp:file.path', eof = 'trp:eof')))
define stream FileReaderStream (code string, serialNo string, amount double, fileName string, eof string); -- Reads from file
@Store(type="rdbms",
jdbc.url="jdbc:mysql://localhost:3306/batchInformation?useSSL=false",
username="root",
password="root" ,
jdbc.driver.name="com.mysql.jdbc.Driver",
isAutoCommit = 'true')
define table AccurateBatchTable(serialNo string, amount double, fileName string, status string, timestamp long);
@sink(type='log', prefix='File to DB copying has Started: ')
define stream FileReadingStartStream(fileName string);
@sink(type='log', prefix='File to DB copying has Finished: ')
define stream FileReadingEndStream(fileName string);
from FileReaderStream
select serialNo, amount, fileName, "test" as status, eventTimestamp() as timestamp, count() as rowNumber, eof
insert into DataStream;
from DataStream
select *
insert into DataStreamPassthrough;
-- Write to DB Passthrough
from DataStreamPassthrough#window.externalTimeBatch(timestamp, 5 sec, timestamp, 10 sec)
select serialNo, amount, fileName, status, timestamp, rowNumber, eof
insert into TemporaryTablePassthroughStream;
-- Log First Record
from TemporaryTablePassthroughStream[rowNumber == 1]
select fileName
insert into FileReadingStartStream;
-- Log Every 100000th Record
from TemporaryTablePassthroughStream
select fileName, rowNumber as rows
insert into FileReadingInProgressStream;
-- Log Last Record
from TemporaryTablePassthroughStream[eof == 'true']
select fileName
insert into FileReadingEndStream;
-- Write to DB
from TemporaryTablePassthroughStream#window.batch()
select serialNo, amount, fileName, status, timestamp
insert into AccurateBatchTable;ETLFileAnalyzer.siddhi
@App:name('ETLFileAnalyzer')
@App:description('This sample demonstrates on moving files to a specific location comparing its content with the header values.')
@source(type='file', mode='REGEX',
dir.uri='file:/Users/wso2/demo/new',
action.after.process='MOVE',
move.after.process='file:/Users/wso2/demo/header-processed',
tailing='false',
@map(
type='text',
fail.on.missing.attribute = 'false',
regex.A='HDprod-[a-zA-z]*-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-([0-9]+)',
@attributes(
expectedRowCount = 'A[1]',
fileName = 'trp:file.path')))
define stream HeaderReaderStream (fileName string, expectedRowCount long);
@source(type='file', mode='LINE',
dir.uri='file:/Users/wso2/demo/header-processed',
tailing='false',
header.present='true',
@map(
type='csv',
delimiter='|',
@attributes(code = '0', serialNo = '1', amount = '2', fileName = 'trp:file.path', eof = 'trp:eof')))
define stream FileReaderStream (code string, serialNo string, amount double, fileName string, eof string);
@sink(type='log', prefix='Accurate Batch: ')
define stream AccurateFileNotificationStream (fromPath string);
@sink(type='log', prefix='Inaccurate Batch: ')
define stream InaccurateFileNotificationStream (fromPath string);
@sink(type='log', prefix='Batch checking started: ')
define stream ExpectedRowCountsStream (fileName string, expectedRowCount long);
define stream AnalyzingLogStream (fileName string, rowCount long);
define table ExpectedRowCountsTable (fileName string, expectedRowCount long, existingRowCount long);
@sink(type='log', prefix='Batch checking finished: ')
define stream ExistingRowCountsStream (fileName string, existingRowCount long);
-- Expected Row Count reader. Moves file from 'new' to 'header-processed'
from HeaderReaderStream[NOT(expectedRowCount is null) and NOT(fileName is null)]
select *
insert into ExpectedRowCountsStream;
from ExpectedRowCountsStream
select fileName, expectedRowCount, -1L as existingRowCount
insert into ExpectedRowCountsTable;
-- Existing Row Count calculator. Moves file from 'header-processed' to 'rows-counted'
from FileReaderStream
select *
insert into FileDataStream;
partition with (fileName of FileDataStream)
begin
from FileDataStream
select fileName, count() as rowCount, eof
insert into #ThisFileRowCounts;
from #ThisFileRowCounts
select fileName, rowCount
insert into AnalyzingLogStream;
from #ThisFileRowCounts[eof == 'true']
select fileName, rowCount as existingRowCount
insert into ExistingRowCountsStream;
end;
-- Existing vs. Expected Row Counts comparer
from ExistingRowCountsStream as S inner join ExpectedRowCountsTable as T on str:replaceFirst(S.fileName, 'header-processed', 'new') == T.fileName
select S.fileName as fromPath, T.expectedRowCount as expectedRowCount, S.existingRowCount as existingRowCount
insert into FileInfoMatcherStream;
from FileInfoMatcherStream
select fromPath, existingRowCount
update ExpectedRowCountsTable
set ExpectedRowCountsTable.existingRowCount = existingRowCount
on ExpectedRowCountsTable.fileName == fromPath;
-- Accurate file mover
from FileInfoMatcherStream[expectedRowCount == existingRowCount]
select fromPath
insert into AccurateFileStream;
from AccurateFileStream#file:move(fromPath, '/Users/wso2/demo/accurate-files/')
select fromPath
insert into AccurateFileNotificationStream;
-- Inaccurate batch file mover
from FileInfoMatcherStream[expectedRowCount != existingRowCount]
select fromPath
insert into InaccurateFileStream;
from InaccurateFileStream#file:move(fromPath, '/Users/wso2/demo/inaccurate-files/')
select fromPath
insert into InaccurateFileNotificationStream;Results¶
The performance statistics of this scenario are as follows:
- Lines : 6,140,031
- Size : 124MB
- Database : AWS RDS instance with oracle-ee 12.1.0.2.v15
- Duration : 1.422 minutes (85373ms)
Consuming messages from a Kafka source and publish to an HTTP endpoint¶
Specifications of EC2 Instances¶
Docker resource allocation¶
| Memory | 3GB |
|---|---|
| CPU | 2 Cores |
Server memory allocation¶
| Xms | 256m |
|---|---|
| Xmx | 1g |
Siddhi applications¶
The following Siddhi applications were used in this scenario:
-
To read messages from a Kafka topic, do a transformation and insert into an in-memory topic:
@App:name('kafka-consumer') @App:description('Reads messages from kafka topics and puts into in-memory-input topic') @sink(type = 'inMemory', topic = "in-memory-input", @map(type = 'passThrough')) define stream ToInMemoryInput (kafkaConsumerInTS long, kafkaConsumerOutTS long, locations string, material string, createdDate string, sid string, headline string, body string, publishTS long, id string); @source(type = 'kafka', topic.list = "test3", threading.option = "single.thread", group.id = "group1", bootstrap.servers = "172.31.39.91:9092", optional.configuration = "auto.offset.reset:latest", @map(type = 'json', fail.on.missing.attribute = "false", enclosing.element = "$")) define stream FromKafkaMessage (locations string, material string, createdDate string, sid string, headline string, body string, publishTS string, id string, updatedDate string); @sink(type = 'log', prefix = '----------------------Kafka Consumer Throughput per second: ', @map(type = 'json')) define stream LogSink (totalEventsPerSec long); @info(name = 'Kafka Consumer Event Timestamp') from FromKafkaMessage select eventTimestamp() as kafkaConsumerInTS, time:timestampInMilliseconds() as kafkaConsumerOutTS, locations, material, str:replaceFirst(createdDate, 'Z', 'GMT') as createdDate, sid, headline, body, time:timestampInMilliseconds(str:replaceFirst(ifThenElse(publishTS is null, updatedDate, publishTS), 'Z', 'GMT'), "yyyy-MM-dd'T'HH:mm:ss.SSSZ") as publishTS, ifThenElse( id is null, 'null', id) as id insert into ToInMemoryInput; from FromKafkaMessage#window.timeBatch(1 sec) select count() as totalEventsPerSec insert into LogSink; -
To filter dynamic headers from incoming data stream
- To read output messages from the in-memory-output topic and publish them to the HTTP client@App:name('Intermediate-process') @App:description('Filter dynamic headers from incoming data stream') @sink(type = "inMemory", topic = "in-memory-output", @map(type = "passThrough")) define stream ToInMemoryOutput (sid string, connectionId string, headers string, data string); @source(type = 'inMemory', topic = "in-memory-input", @map(type = 'passThrough')) define stream FromInMemoryInput (kafkaConsumerInTS long, kafkaConsumerOutTS long, locations object, material object, createdDate string, sid string, headline string, body string, publishTS long, id string); @info(name = 'Filter Heards Messages') from FromInMemoryInput select sid, "test_connectionId" as connectionId, "'connectionId:test_connectionId','appKey:workManWork','Content-type:application/json'" as headers, str:fillTemplate(""" { "type": "heards_sub_resp", "publishTS": {{publishTS}}, "dynamicAppInTS": {{dynamicAppInTS}}, "dynamicAppOutTS": {{dynamicAppOutTS}}, "kafkaConsumerInTS": {{kafkaConsumerInTS}}, "kafkaConsumerOutTS": {{kafkaConsumerOutTS}}, "headline":"{{headline}}", "body":"{{body}}", "id": "{{id}}", "material": {{material}}, "locations": {{locations}}, "createdDate": "{{createdDate}}", "sid":"{{sid}}", "correlationId":"{{correlationId}}" }""", map:create( 'headline', headline, 'body', body, 'id', id, 'material', json:getString(material, '$'), 'locations', json:getString(locations, '$'), 'createdDate', str:replaceFirst(createdDate, 'GMT', 'Z'), 'sid', sid, 'publishTS', publishTS, 'dynamicAppOutTS', time:timestampInMilliseconds(), 'dynamicAppInTS', eventTimestamp(), 'kafkaConsumerInTS', kafkaConsumerInTS, 'kafkaConsumerOutTS', kafkaConsumerOutTS, 'correlationId', 'Test123')) as data insert into ToInMemoryOutput;@App:name('ws-publisher') @App:description('Reads from in-memory-output topic and publishes messages to client') @source(type = 'inMemory', topic = "in-memory-output", @map(type = 'passThrough')) define stream fromInMemoryOutput (sid string, connectionId string, headers string, data string); @sink(type = 'http', method = "POST", publisher.url = "http://172.31.39.177:8280/services/TestProxy", headers = "{{headers}}", on.error = "LOG", max.pool.active.connections="1000", ssl.verification.disabled = "true", @map(type = 'json', @payload("""{"data":{{data}} }"""))) define stream ToWsClient (data string, wsPublisherOutTS long, headers string, connectionId string, sid string); @sink(type = 'log', prefix = '----------------------WS Publisher Throughput per second: ', @map(type = 'json')) define stream LogSink (totalEventsPerSec long); @info(name = 'Add Filtered Message Timestamp') from fromInMemoryOutput select json:toString(json:setElement(json:setElement(json:toObject(data), '$', eventTimestamp(), 'wsPublisherInTS'), '$', time:timestampInMilliseconds(), 'wsPublisherOutTS')) as data, time:timestampInMilliseconds() as wsPublisherOutTS, headers, connectionId, sid insert into ToWsClient; from ToWsClient#window.timeBatch(1 sec) select count() as totalEventsPerSec insert into LogSink;
Results¶
-
Memory consumed: 1g
-
TPS: 10,000
Consuming messages from a CSV file and publish to a MySQL table¶
Specifications of EC2 Instances¶
Docker resource allocation¶
| Memory | 8GB |
|---|---|
| CPU | 4 Cores |
Server memory allocation¶
| Xms | 2g |
|---|---|
| Xmx | 4g |
Siddhi application¶
@App:name("FileToRdbms")
@App:description("Description of the plan")
@store(type='rdbms' , jdbc.url='jdbc:mysql://172.31.18.173:3306/purchesOrder?useSSL=false',username='root',password='root',jdbc.driver.name='com.mysql.jdbc.Driver')
define table PurchesOrderTable (orderID string, numberOfItems int, totalValue double, paymentStatus string, deliveryAddress string );
@source(type='file', mode='line',
file.uri='file:/home/ubuntu/csv/productTable.csv',
tailing='false',
action.after.process='MOVE',
move.after.process='file:/home/ubuntu/csv/moved',
@map(type='csv', delimiter=','))
define stream InventoryUpdate (orderID string, numberOfItems int, totalValue double, paymentStatus string, deliveryAddress string);
@async(buffer.size='4096', workers='2', batch.size.max='5000')
define stream IntrimEventStream(orderID string, numberOfItems int, totalValue double, paymentStatus string, deliveryAddress string);
from InventoryUpdate
select *
insert into IntrimEventStream;
from IntrimEventStream
select *
insert into PurchesOrderTable;
from InventoryUpdate#window.timeBatch(1 sec)
select count() as throughput
insert into OutputStream;
from OutputStream#log('TPS: ')
insert into TempStream;Results¶
-
Memory consumed: 2.56g
-
TPS: 9,000
Monitoring a database table in MySQL and publishing data to a Kafka topic¶
Specifications of EC2 Instances¶
Docker resource allocation¶
| Memory | 8GB |
|---|---|
| CPU | 4 Cores |
Server memory allocation¶
| Xms | 2g |
|---|---|
| Xmx | 4g |
Siddhi applications¶
@App:name("PurchaseOrderSiddhiApp")
@App:description("Description of the plan")
--@sink(type='log')
@source(type = 'cdc', url = "jdbc:mysql://172.31.18.173:3306/order?useSSL=false", username = "root", password = "root", table.name = "PurchesOrders", operation = "insert",
@map(type = 'keyvalue', fail.on.missing.attribute = "false"))
define stream PurchesOrderStream (orderID string, numberOfItems int, totalValue double, paymentStatus string, deliveryAddress string );
@sink(type='kafka',
topic='delivery_items_topic',
bootstrap.servers='172.31.3.169:9092',
partition.no='0',
@map(type='xml'))
define stream kafkaPublisherStream(orderID string, numberOfItems int, totalPayable double, deliveryAddress string);
@sink(type='log')
define stream kafkPubTps(pubCount long);
@sink(type='log')
define stream publishTps(recCount long);
from PurchesOrderStream[paymentStatus =='cod' or paymentStatus=='paid']
select orderID, numberOfItems, ifThenElse(paymentStatus=='cod', totalValue, 0.0) as totalPayable, deliveryAddress
insert into kafkaPublisherStream;
from PurchesOrderStream#window.timeBatch(1 sec)
select count() as recCount
insert into publishTps;
from kafkaPublisherStream#window.timeBatch(1 sec)
select count() as pubCount
insert into kafkPubTps;Results¶
-
Memory Consumption: 1.5g
-
Time taken: 46 minutes
-
Data set size: 34,330,327
Read XML file and mapping to a stream¶
Specifications of EC2 Instances¶
Docker resource allocation¶
| Memory | 8GB |
|---|---|
| CPU | 4 Cores |
Server memory allocation¶
| Xms | 2g |
|---|---|
| Xmx | 4g |
Siddhi applications¶
@App:name("NodesConvertor")
@App:description("Description of the plan")
@source(
type = 'file',
file.uri = "file:/home/ubuntu/csv/input.xml",
mode = "line",
tailing = "false",
action.after.process='keep',
@map(type='xml',
enclosing.element="/osm/node",
enclosingElementAsEvent="true",
enable.streaming.xml.content="true",
fail.on.missing.attribute="false",
@attributes(id = "/node/@id", lat = "/node/@lat", lon = "/node/@lon", version = "/node/@version", timestamp = "/node/@timestamp", changeset = "/node/@changeset")))
define stream FooStream (id string, lat string, lon string, version string, timestamp string, changeset string);
@info(name = 'totalQuery')
from FooStream#window.timeBatch(1 sec)
select count() as throughput
insert into OutputStream;
from OutputStream#log('TPS: ')
insert into TempStream;Results¶
-
Memory consumption: 1.2g
-
TPS: 40,000
Reading an XML file and publishing to a Kafka topic¶
Specifications of EC2 Instances¶
Docker resource allocation¶
| Memory | 8GB |
|---|---|
| CPU | 4 Cores |
Server memory allocation¶
| Xms | 2g |
|---|---|
| Xmx | 4g |
Siddhi applications¶
@App:name("NodesConvertor")
@App:description("Description of the plan")
@source(
type = 'file',
file.uri = "file:/home/ubuntu/csv/input.xml",
mode = "line",
tailing = "false",
action.after.process='keep',
@map(type='xml',
enclosing.element="/osm/node",
enclosingElementAsEvent="true",
enable.streaming.xml.content="true",
fail.on.missing.attribute="false",
@attributes(id = "/node/@id", lat = "/node/@lat", lon = "/node/@lon", version = "/node/@version", timestamp = "/node/@timestamp", changeset = "/node/@changeset")))
define stream FooStream (id string, lat string, lon string, version string, timestamp string, changeset string);
@sink(type='kafka',
topic='kafka_result_topic',
bootstrap.servers='172.31.3.169:9092',
partition.no='0',
@map(type='xml'))
define stream kafkaStream(id string, lat string, lon string, version string, timestamp string, changeset string);
@info(name = 'totalQuery')
from FooStream#window.timeBatch(1 sec)
select count() as throughput
insert into OutputStream;
from OutputStream#log('TPS: ')
insert into TempStream;
from FooStream
select *
insert into kafkaStream;Results¶
-
Memory consumption: 1.7g
-
TPS: 38,000